

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2010.

The Journal Article Tag Sets were designed as translation targets; they are permissive, descriptive rather than prescriptive, and use escape hatches to preserve as many semantics as possible in born-digital XML content that originates in another tag set. This means that the Tag Sets can describe “almost” anything for “almost” anybody, but they may fail to hit the sweet spot for XML production.
The Journal Article Tag Sets can be used right out of the box, and many users do just that. But for a publisher (particularly a publisher looking to move XML to earlier stages in a workflow) or for an archive with requirements to regularize content, the advantages to subsetting can be substantial. A subset leaves all the documents valid to one of the original NLM Tag Sets at the same time it enables business-specific reporting, Quality Assurance, and XML tool use.
Subsetting can eliminate unimportant and meaningless variation that makes all work with a tag set more difficult and time-consuming. An organization can tighten loose models; eliminate elements and attributes that are the twenty percent of the 80/20 rule that they do not need; and provide specific attribute values where the Tag Sets permit any data characters. There are advantages to a leaner tag set for controlling conversion vendors and interchanging with aggregators and business partners. But the largest gains may be in ease-of-use for XML copy-editors and faster ramp-up for the developers building web applications.
Subsetting makes the most sense for XML-first workflows when copy-editing is performed in XML; when a publisher or archive relies on non-subject-matter-expert conversion vendors; and when there are more than a handful of complex output products produced from the XML.
This paper could have been entitled “Making the Business Case for Subsetting a JATS Tag Set”; it deals with the business rationale for the work of cutting down one of the Journal Article Tag Sets as they are distributed. In a sense, it speaks to all subsetting of standard vocabularies in XML. This material is directed toward technical strategists of XML Publishing systems and departments and (as ammunition for persuading such managers and strategists) to the technical developers constructing and maintaining XML publishing systems.
Familiarity with the Journal Article Tag Suite or one or more of its Tag Sets is assumed, but should not be necessary, except for following a few of the more detailed examples in the paper. This paper does assume familiarity with XML tagging, elements, attributes, and the rationale for XML single-sourcing.
Background
The Journal Archiving and Interchange Tag Suite (on the path to becoming a NISO standard) provides a set of XML schema modules that define elements and attributes that can be used to describe the textual and graphical content of journal articles. The intent of the Suite is to provide a common XML language in which publishers, archives, aggregators, web designers, authors, and other communities can exchange journal content. This journal content is defined as both research articles and some non-article journal material such as letters, editorials, obituaries, and book and product reviews.
A “tag set” is a particular arrangement of elements and attributes that model a single document type (such as a journal article) for use in XML tagging. Tag sets can be built using the modules of the Suite, thus using the elements and attributes defined by the Suite, but in a particular arrangement defined by the tag set. Thus the definitions of the elements and attributes are established by the Suite, but the particular element content and attached attributes are established by a tag set.
The JATS Tag Sets
The National Library of Medicine (NLM) makes available three journal article tag sets (also on track to becoming NISO standards): known informally as the Archiving Tag Set, the Publishing Tag Set, and the Authoring Tag Set. Each provides an XML definition for a journal article, but they vary in strictness of modeling, flexibility, and expressiveness.
The three Tag Sets were designed as translation targets; they are permissive, descriptive rather than prescriptive, and use escape hatches to preserve as much semantics as possible in born-digital XML content that originates in another tag set. This means that one of the Tag Sets can describe almost anything for almost anybody, but may fail to hit the sweet spot, particularly for XML production. Thus while archives and libraries may be very happy with the Tag Sets, publishers and web developers tend to want the Tag Sets in a more reduced form.
Using the Tag Sets
A publisher or other organization that decides to use one of these Tag Sets for their XML tagging may use one of several techniques for choosing how to make use of the Tag Set:
- Use one out-of-the-box. The organization can choose one of the Tag Sets and use it (without alteration) to tag their XML documents.
- Create an “informed-by” tag set. The organization can base a DTD/schema that they develop for their own content on one of the JATS Tag Sets. They may (or may not) choose to follow the style, customization mechanisms, naming conventions, etc. of the chosen Tag Set. They use as many elements and attributes as they can from the published Tag Set as they build a tag set of their own. They may copy wholesale or only borrow a few components.
- Customize one of the Tag Sets. The JATS Tag Sets are distributed with a straightforward customization mechanism. An organization can choose to use this mechanism to create a superset of a JATS Tag Set (using nearly all of the Tag Set and adding their own material) or cut down one of the distributed Tag Sets to create a subset of a JATS Tag Set.
So, subsetting a JATS Tag Set can be defined as cutting down one of the existing Tag Sets to make it smaller and more manageable. Subsetting makes the Tag Set simpler by eliminating complexity and removing unused components. Such a reduced Tag Set is easier to manipulate, document, learn, and use (easier implies cheaper and faster as well).
Why Make a Subset?
In asking why making a subset has these advantages, we are really asking why not use one of the Journal Article Tag Sets out of the box, as they are distributed? The answer, in a word, is “quality”. Everybody wants quality, but in a DTD/schema/tag set quality may be difficult to define. The best indication of quality in a tag set is, is it a “good match for its purpose”?
Consider the Original JATS Rationale. The primary purposes of the Journal Article Tag Sets are to:
- Act as a transformation targets,
- Capture current journal tagging practice, and
- Be inclusive and descriptive not prescriptive or controlling.
By providing a common vocabulary, the published Tag Sets work best for transformation and interchange. The use cases most considered during the design include the following:
- Two publishers with proprietary tag sets convert into one of the Tag Sets for interchange between themselves.
- An aggregator/website-host converts each publisher’s proprietary tag set to JATS so that a coherent web presence can be designed.
- An archive/library (the exemplars are PubMed Central and Ithaka’s Portico) has many publisher’s tag sets coming into its repository, but a single tag set preserved in the archive. All of these proprietary tag sets are converted into one of the JATS Tag Sets.
The JATS Tag Sets are now used for many other purposes such as single source publishing, eBooks, interactive websites, RSS/Atom syndication, print publication, etc., many of which involve production using XML. The Tag Sets preform very well in these new modes. But an organization considering using one of the Tag Sets should compare the original purposes/goals of these Tag Sets with the organization’s own purposes/goals. If the organization is doing many other things besides multi-input transformation and transformation for interchange, the JATS Tag Sets (as published) have not been optimized for the organization’s prime purposes. Does this imply that an organization should not use JATS? Not at all, but JATS should be used intelligently and made to fit the purposes of the organization. “Fit to purpose” may entail building a subset.
JATS Captures Current Tagging Practice. By design, the JATS Tag Sets do not set tagging Best Practice, enforce Best Practice, reward Best Practice, or even, in many cases, make explicit what should be considered as Best Practice. JATS was designed from a study of many existing journal DTDs, one schema, and an overview of thousands of journals. The intent was to design a tag set that could capture most (better than 80-20 was the goal) of what current journal publishers were doing. Therefore, if a number of publishers tag it, there should be a way to capture that in JATS. JATS may capture it directly (the JATS element <disp-quote> can capture block quotes, display quotes, shout quotes, and epigraphs) or there may be a simple transformation used to capture the semantics (JATS has no element for <gene>, but an escape-hatch element <named-content content-type="gene"> can be used to preserve the semantics). JATS allows multiple approaches to common structures; there is no one right way specified by the JATS. In other words, if there are five different common ways to tag something, JATS should handle all five.
JATS is Descriptive not Prescriptive. JATS was designed to be descriptive (to tag what is there) rather than enforcing element organization or sequence. JATS was designed to be inclusive to preserve as much existing semantic tagging as possible, so as not to throw away intellectual effort expressed in documents being converted to JATS from another form.
JATS is fairly non-enforcing:
- Almost no element or attribute is required.
- There is very little required sequence. (Metadata is presented in a loose order, but little else has specific order at all, and the metadata will accommodate many existing arrangements.)
- The element content models contain many large OR groups (which translate to “place any of these elements here, as many as needed, in any order, or none at all”).
JATS is Not All Things to All People. The implications of all these design decisions are that JATS is made to describe the whole journal publishing world, not any particular organization’s piece of it. JATS may not help sufficiently in enforcing specific business rules, making tagging practices consistent, or regularizing content for archival or publishing processes.
The Business Case: The High Cost of Too Many Options
The cost of supporting unused and unwanted elements is rarely considered as a cost factor when designing a tag set. Thus it seems very easy to reject customizations, after all, customizations cost time and money. But supporting too many options also costs time and money, although the costs are not itemized in a budget line in the same way.
As an example, look at a Bibliographic Reference List, the list of cited material at the end of an article (<ref-list>). We know it when we see it, but just what is a Reference List? Here is a small sample:

Even in this simple example there are (or may be) complications. Are the two paragraphs that precede the list part of the list or not? Are paragraphs and other block elements allowed at the start of the such a list, or not as part of the list? (The Publishing Tag Set allows it to be tagged either way.) Are labels on the individual citations (here simple counting numbers) always present? Are they generated? For a particular organization, are Reference Lists allowed to be recursive, with separate interior lists, for example, directed toward different audiences?
Here, written out as words, is the Publishing Tag Set model for a <ref-list> element:
Publishing Tag Set Reference List Model (words)
A ref-list contains the following, in order:
- <label> Label (Of a Figure, Reference, Etc.), optional
- <title> Title, optional
- Any combination of
- All the block display elements:
- <address> Address/Contact Information
- <alternatives> Alternatives For Processing
- <array> Array (Simple Tabular Array)
- <boxed-text> Boxed Text
- <chem-struct-wrap> Chemical Structure Wrapper
- <fig> Figure
- <fig-group> Figure Group
- <graphic> Graphic
- <media> Media Object
- <preformat> Preformatted Text
- <supplementary-material> Supplementary Material
- <table-wrap> Table Wrapper
- <table-wrap-group> Table Wrapper Group
- <disp-formula> Formula, Display
- <disp-formula-group> Formula, Display Group
- <p> Paragraph
- <def-list> Definition List
- <list> List
- <tex-math> Tex Math Equation
- <mml:math> Math (MathML 2.0 Tag Set)
- <related-article> Related Article Information
- <related-object> Related Object Information
- <disp-quote> Quote, Displayed
- <speech> Speech
- <statement> Statement, Formal
- <verse-group> Verse Form for Poetry
- <ref> Reference Item, optional
- <ref-list> Reference List (Bibliographic Reference List), optional
Here’s a graphical representation of the same model, to show the amount of complexity:
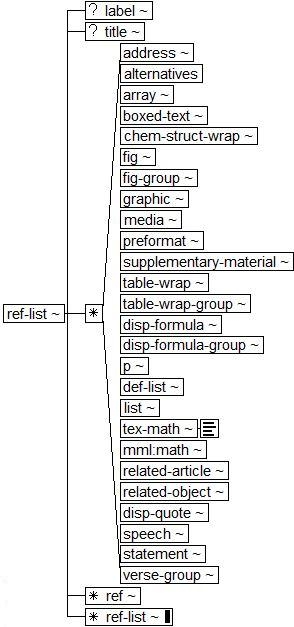
This is a fine and complex model, able to handle nearly anything a publisher can throw at it; but for publishing and processing, it is both too much and too little. The “too much” is obvious, within a Reference List there may be: figures, definition lists, tables, groups of tables, math, related-article references (and poetry and speeches and hypotheses and code fragments and...)!
The “too little” is slightly more subtle, but equally painful from the point of view of processing or designing output products (not a JATS goal remember!):
- Nothing, not even the references element (<ref>), is required. This means that XML parsing cannot be used for QA. Business rules (in Schematron, for example) will need to be written to confirm that the Reference List contains References. This is also no help in conversion/authoring.
- There is no way to tell if labels and prefixes (<label>) are (or should be) generated.
- There is no way to tell if a title (<title>) should always be present in the data (e.g., Because the organization has four different wordings of the title of such a list) or always be generated (e.g., Since all Reference Lists on the website must have the same title). A common rule for processing is to use a title if there is one in the data and to generate a title (e.g., Bibliography) if there is not. The model gives no guidance about what to do.
In contrast, here is a very likely subset of the References List, that removes almost all the complexity in the content model for Reference Lists:
Subset Reference List Model (words)
- A ref-list contains the following, in order:
- <title> Title, optional
- <ref> Reference Item, required and repeatable
And here is the graphical model of the subset:
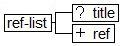
This much simpler (but adequate for many publishers) subset still leaves the issue of the title unclear, but provides some very concrete gains:
- At least one Reference (<ref>) is now required inside the list.
- Labels are always generated on display by this organization, so no labels are allowed in the XML source file. This lets an XML parser check for the presence of incorrectly added labels. Now a conversion vendor cannot possibly make labeling mistakes, and neither can a copyeditor.
- Twenty-eight (28) elements are no longer allowed in this context, which saves significantly by reducing development and processing complexity. Human editing has been made easier as well, since there is so much less to think (worry, ponder, waste-time) about.
Too Many Options Cost Time and Money
Processing and designing for elements and attributes that are not needed or used increases 1) development complexity, time, and costs; 2) downstream processing complexity, time, and costs; 3) conversion complexity and errors; 4) QA complexity and headaches; 5) consistency problems in archival stores, as well as having 6) a negative impact on training/understanding and thought and motion complexity in human editing.
Development/Downstream Processing. When an element is named in a tag set, the XML system must:
- Be prepared to create the element (and all its attributes),
- Be able to store it, in all its contexts,
- Be prepared to format it, in all display formats,
- Account for it (included or excluded) in every transformation written,
- Figure out how to perform QA for it, and
- Test it in most of its contexts.
Therefore extra elements can lead to added complexity of every transformation specified and tested, added complexity in design of the data store(s), added complexity of every display format specified, and additional tests with more test cases. With a larger (but not usefully larger) tag set, all development is more complicated!
When elements are useful and necessary, this cost is just the price of doing business. But extra, unused, unwanted elements can mean an order of magnitude burden for any of the processing steps built on the XML files. There is potential added complexity in every transformation performed as well for as every display format produced (print styles, web styles, eBook styles). So, ask the question: two elements or 30 elements figured into all these processes?
Software Customizations. One of the ways many organizations boost acceptance of XML among their personnel and streamline their XML production operations is to customize their XML tools. The XML tool involved may be an XML data repository, a Word-to-XML conversion facility, an XML editor, a web-based input package, an XML-based composition system, filters into and out of a page makeup system such as InDesign, an XML data aggregator, or other XML processing package. Tool customization typically entails setting up profiles and preferences, designing or modifying user interfaces, writing scripts and filters, and modifying the coding for software packages. Most XML tools are not intended to be used out-of-the-box, and even the ones that are can be made to work more smoothly and more in line with an individual’s work habits and knowledge. Making the XML user’s job easier is one of the great services of XML tools, and each tool can be greatly aided in this through a well-thought-out customization. Creating a tag set subset is one of the first and simplest customizations, that can make all the rest of the customizations need to do less work.
Conversion. Too many options at conversion time can mean increased complexity of conversion. This may include increased length and complexity of instructions to conversion vendors (or conversion programs), the amount of expertise and thought required of the conversion vendor (or complexity of the programming rules), and increased time and energy needed for the conversion. But, leaving all of those aside, the largest cost of conversion complexity is the likelihood of conversion error, variations in tagging practice between vendors or over time. Bluntly put, if there is one way to tag it, the database will show one or two different styles. If there are five ways to tag it, the database will show four to seven.
Quality Assurance and Quality. More elements mean increased responsibilities for QA, both because additional QA is necessary and because there is an increase in time and energy to find and regularize meaningless variation. With loose models (as all the Tag Sets have, even Authoring, which is the most strict), there is a decreased value of models and XML parsing for checking documents. This will produce a need for more rules-based (such as Schematron) and/or people-based QA. With that many more elements, more can go wrong.
Fig. 1A Sample Reference List
The hidden cost implied here is the cost of inconsistency in an Archive over time (a tagging quality issue). As an example, look again that the sample Reference List above. A conversion vendor might tag that list as a Reference List, that contains a title (“References”), followed by two paragraphs (still inside the list), followed by a the list of cited references. But consider, a publisher might prefer this list tagged as a section, that contains a title (“References”), followed by two paragraphs (inside the section), followed by a title-less list of cited references. There is no guidance in the Tag Set as to which way to code this material, and therefore different conversion vendors (or even the same conversion shop over time) may choose one way one time and then the other for a different article.
Consistency over time improves the quality of the archive in respect to search and retrieval, as well as content reuse and display.
Simplified Human Editing
Last, but definitely not least, are the effects of extraneous elements on human editing. While very few journal articles are authored in XML, many are edited (both copyediting and content edited) during publication production, during QA, or as part of the archiving process.
XML editing software tools frequently display a list of elements that are valid in a given context as a pull-down list, pop-up menu, sidebar, or secondary window. The following picture shows an element selection window in the oXygen editing tool. The context (where the cursor is placed) is directly inside the Reference List, just after the <title> element. The list of elements tells a human editor what the Publishing Tag Set specifies as legal elements at this point in the document:

Fig. 2What an Editor Sees for Possibilities (inside a Reference List)
The following picture shows an element selection window in the oXygen editing tool, in the same context (where the cursor is placed) for the smaller subset Tag Set already discussed:
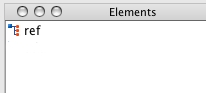
Fig. 3What an Editor Sees for Possibilities (inside a Reference List)
Consider this visual and processing complexity in terms of human productivity. Consider the very useful web optimization adage “Don’t Make me think!”. There is no way to quantify this gain, without running time and motion studies no one will pay to run, but it may be the most significant reason of all to create a subset. The importance of ease-of-human-use should be considered in textual XML processing.
Training. Extraneous options can also impact training and understanding. XML schemas (DTD, XSD, RELAX NG) are communications devices. They are used to teach a tag set to a conversion vendor, a conversion programmer, aggregators and archives, web designers, print designers/compositors, business partners, tag set maintainers, and an organization’s own employees. Look again at the Reference List example and picture writing training material for it and explaining all the distinctions. Element complexity can also affect understanding. When a subset is stripped down to the elements the people actually use on a daily basis, there is much more buy-in and understanding of the function of the remaining elements.
What it Means to Make a Subset
In a nutshell, making a subset means making complex models into simpler ones, removing meaningless variation, providing specific values for attributes (instead of just data characters), and removing unnecessary elements.
Simplifying Models. The bread and butter of subsetting is making complex content models into simpler ones. One very good example of this has already been illustrated, restricting a Reference List.
As a second, more complex example, consider article metadata (<article-meta>). This is the article-level header information such as who wrote the article, the article title, the publication date, and the volume and issue of the journal. The current Publishing Tag Set includes 37 elements inside article metadata, in the following content model:
(article-id*, article-categories?, title-group, (contrib-group | aff)*, author-notes?, pub-date+, volume?, volume-id*, volume-series?, issue?, issue-id*, issue-title*, issue-sponsor*, issue-part?, isbn*, supplement?, ((fpage, lpage?, page-range?) | elocation-id)?, (email | ext-link | uri | product | supplementary-material)*, history?, permissions?, self-uri*, related-article*, abstract*, trans-abstract*, kwd-group*, funding-group*, conference*, counts?, custom-meta-group?)
A subset known to me (for a large publisher) uses just 15 elements in article metadata, in the following content model:
(article-id*, article-categories+, title-group, contrib-group*, pub-date+, volume?, issue?, fpage, lpage?, (uri | supplementary-material)*, history?, permissions?, abstract*, kwd-group*)
Creating this subset has (among other advantages):
- Eliminated one way to associate affiliations with authors.
- Eliminated the possibility of tagging a <page-range> and failing to tag the more important <fpage>.
- And removed 21 unused elements:
- volume and issue information that do not exist for this publisher (volume-id, volume-series, issue-id, issue-title, issue-sponsor, and issue-part);
- metadata that this publisher does not collect for journal articles (isbn, supplement, page-range, elocation-id, product, related-article, trans-abstract, funding-group, conference, and counts);
- and escape-hatch customizations and linking mechanisms (author-notes, email, ext-link, self-uri, and custom-meta-group).
Removing Meaningless Variation. Variation in how an article is tagged should be meaningful; a component should be tagged as a section because it is a section or as a Reference List because it is one, and not because that was one convenient way to make the XML tagging valid. As an example, consider how the Tag Sets associate authors (<contrib>) and affiliations (<aff>). The Publishing Tag Library documents four locations in which to place an author’s affiliation, and several ways to make the connection between author and affiliation. All of them place authors and affiliations into an article. One of them is a fairly bad idea (“textual affiliation”). How many organizations really need all three of the others? Consider writing the instructions to the conversion vendor or program. Is there a style guide or explicit instructions determining which an organization prefers? Will anything prevent getting two or even three of these styles in the archive?
Providing Specific Values for Attributes. The unmodified Tag Set defines the values of many attributes merely as any data characters, with no guidance provided. Many organizations and their processing departments restrict attribute values, and use those values to control processing. For example:
- Document identifier and object identifier might be DOIs, ISBNs, publisher-specific IDs, etc. It is unlikely that an organization is prepared to support an infinite list.
- Citations can assigned a @publication-type of journal article, book, communication, letter, review, conf-proc, list, patent, thesis, discussion, report, standard, working-papers, etc. QA may depend heavily on this value (journal articles have issues and first pages; cited books have publishers and overall lengths). If the type of citation can be figured out, shouldn’t it be recorded consistently?
- The attribute specific-use may be used to mark content (such as a paragraph, note, or section) that only appears in one format (“web-only”, “print-only”, “voice-only”); is intended for a particular audience (“for-teachers” and “for-students”) or (“for-doctors”, “for-nurses”, and “for-patients”), or is “sensitive” and thus not shown to all audiences. One can imagine many complex behaviors based on the information supplied by this attribute, but not if the values are all over the map, randomly. One person says “web-only”, a second person says “online”, and a third says “eContent”, and they all mean the same thing.
- Many many publishers and aggregators want a small controlled list of media types. Data character content makes such a list infinite.
Removing Unused Values for Attributes. It is also possible (but probably less useful) to remove never-used attribute values. For example, the Publishing Tag Set allows many types of cross-references, for example references to plates, schemes, and keywords. If values are there, they can be pulled off a picklist by accident; consider the result for processing. As another example, the type attribute for <person-group> can be used to name the role of the contributors in a cited reference: all authors, all translators, etc. But values for directors, guest editors, and inventors are also permitted.
Removing Unused Elements. This one is more controversial, but I believe equally necessary. Are unused elements just benign presences or does the existence of an element provide an implicit warrant to use it? Leaving in those elements will allow us to expand and use those elements someday, people will say. Current programming practice stresses building what you need now and in the immediate future, not all the possibilities that you can envision. Tag sets operate on similar principles. Consider: If an element is not in an organization’s tag set, then no one will ever (can ever):
- Use it incorrectly or commit tag abuse with it;
- Use in a correct but suboptimal way;
- Accidentally choose it from a menu;
- See it or be confused by it on a menu;
- Transform it incorrectly;
- Spend a lot of time writing transform/QA/loader code for it, to get all the cases right; or
- Display it in an ugly way.
As an example, the Publishing Tag Set allows text plus 36 elements inside a title (<title>). Each of these 36 elements may be (indeed undoubtedly is) needed by some publisher, but few, if any, publisher needs all of them. For example, does a title need to contain: 3 kinds of external links; related articles, related objects and inline supplementary material; chemical structures (display form), both inline equations and MathML; overlines and underlines; milestone elements to mark overlapping structures, small caps (a formatting issue), NLM citations (an older deprecated element), three kinds of internal links, or a bucket element to hold graphical alternatives? The very expansiveness that makes the Tag Set so usable for an archive can add a burden for a publisher.
There are many elements that can be removed painlessly, for example:
- Counts (table count, figure count, et al.). If an organization does not retain this information, it can safely remove 7 elements.
- Conference metadata. If an organization does not record this information, it can safely remove 7 elements.
- Emphasis. Note that every emphasis element will need to be expressed in any formatting designs, page or web specifications, and composition or formatting programs.
- The Archiving Tag Set has 13 emphasis elements: <bold>, <italic>, <monospace>, <overline>, <overline-start>, <overline-end>, <roman>, <sans-serif>, <sc>, <strike>, <underline>, <underline-start>, and *<underline-end>
- The Publishing Tag Set has 9 emphasis elements: <bold>, <italic>, <monospace>, <overline>, <roman>, <sans-serif>, <sc>, <strike>, and <underline>.
- A subset produced recently has 5: <bold>, <italic>, <monospace>, <sans-serif>, and <sc>.
Other Element Considerations. Some elements are particularly troublesome as well as subject to abuse. When they are needed, they are needed. But if they are not needed, never used, and merely left over, the following elements can cause headaches because of their inherent complexity, the amount of knowledge it takes to understand their nuances, and the amount of extra processing work they entail:
- <subarticle>. Determining when an article is divided into subarticles, versus divided into sections, versus all the smaller components tagged as separate articles is an art not a science and varies from publisher to publisher (and even journal to journal). Is that News of the Week an overarching article with many small news subarticles or this that just an article with many sections? A subarticle is allowed to repeat all of the metadata for the article, but not required to do so. These facts lead to a nearly infinite inconsistent ways to treat subarticles. Subarticle tagging needs to be negotiated between interchange partners.
- <response>. Responses, like subarticles, are in the mind of the beholder and need negotiation.
- <custom-meta> and <named-content>. These elements are the basic catch-alls that make the Tag Sets so robust. They may be used to handle almost any semantic tagging that a publisher needs to preserve. However, they have not inherent structure or semantics of their own. They need to be negotiated between (or among!) business partners, publishers and archives, aggregators, libraries, and other receiving institutions.
- <supplementary-material>. Supplementary material is a perennial problem. Where does it live? Is it inside the article? Is it shipped with the article? Is it an external dataset or other file stored with the publisher? Is it a public dataset (such as GeneBank) stored by an organization other than the publisher? In any case, how is the supplementary material tied to the text of the article? How much metadata should be made available? Since the purpose of these Tag Sets is to permit all these variations, business/interchange partners and archives and libraries should establish guidelines for communicating with each other.
- <sec-meta>. Section metadata is more common in books than in journal articles. However, if it is used, a few of the areas necessary for agreement include: whether to use it at all; how much metadata and which elements; how is this metadata related to article metadata?
Subsetting Answers the Charges
Is subsetting the answer to all the challenges in life? Does everyone need to subset? Of course not. But some of the reasons given for not creating a subset fall apart on closer examination.
My Conversion Vendor can Handle the Full Tag Set. Yes, they can. But they can do so faster and more accurately with a subset. A properly designed subset may lead to an increase in speed or a decrease in price, but even if it does neither, there will be an increase in quality. Many conversion vendors prefer subsets; they feel that a subset makes their lives easier, provides fewer choices, and improves their quality (they also strive for high quality).
Subsetting Costs Time and Money. Yes, it does. First it requires analysis, so that the organization knows exactly what it can easily and effectively give up. This is the complex and expensive part of the subsetting, because it involves an organization’s knowledgeable staff. Then someone must write and test the subset. This is the cheaper and easier part of the expense, since the Tag Suite is designed for subsetting, and heavily parameterized to make it convenient to cut down. Writing and testing a subset needs a trained XML professional, but their job should not be difficult or expensive.
Subsets Need to be Updated When the Tag Set is Revised. Actually, it depends. Even if an organization intends to stay current with the latest releases, the answer is maybe yes and maybe no. Historically, most changes to the Tag Sets involve adding optional features. Most of the subsetting changes an organization is likely to make do not break with such additions. For example, there used to be 14 items in an OR group, a particular customization deleted 8. With the new release, there are now 16 objects; no change is necessary. As another example, an organization has changed the article metadata as was just discussed. Four new optional items are added to the metadata sequence. If an organization wants any of the four, they must add them to their customization. It not, there is no change. For many update releases, a subsetter can replace all the old modules in the Suite with new modules, and ignore all changes.
The only issues arise for major releases, where non-backwards-compatible changes have been made. The Change Reports distributed with the Tag Set releases typically explain which changes might affect customizations.
For all releases, an organization will need to examine the new material for components and options they want, but this is true whether a subset has been made or not.
Does Customization Come at the Expense of Standardization? No, it does not. A document valid to an organization’s subset is also valid to the unaltered Tag Set. Such a subset document is “valid according to” or “conformant to” or any other claim made for a non-subsetted document.
But What if Somebody Needs a ... Chemical Structure? Picture this scenario: A subset tag set has been created, leaving out the element for a chemical structure (<chem-struct>). Time passes and the requirements have changed — there is now a need for chemical structures, and the organization can afford to tag them and proof them and format them. To add chemical structure back, a number of steps will need to be taken:
- Add <chem-struct> back to the subset as a block-level object,
- * Add <chem-struct> to each transformation in production,
- * Add the formatting for <chem-struct> to each display,
- * Inform all business partners of the new element,
- * Update the Tag Set documentation, and
- * Change the conversion instructions and tests to include chemical structure.
But all the asterisked items would have been done initially if <chem-struct> had been included from the beginning. They would also have been done for all the other elements that were also not included in the subset. And now a very good estimate can be made of the cost of such a change.
Is Subsetting Right for Your Organization?
Having established that subsetting is not always the best process, how can an organization judge whether subsetting is best within its processing structure?
Creating a subset has the biggest payoff when:
- Humans are authoring in this tag set. (This happens rarely in journal publishing.)
- Humans are editing these XML files using XML editing software.
- Processing (and therefore QA) has strict requirements.
- There is a need for consistency across multiple vendors.
- There is a need for consistency over time.
Subsetting is still very nice to have, and frequently provides better results than out-of-the-box Tag Sets, when:
- There are limited resources for QA, development, and maintenance.
- An organization uses many different conversion vendors.
- Conversion vendors/processors do not understand the narrative content, they only know XML.
Conclusion
Although the JATS Tag Sets can be used right out of the box, and many users do just that, for a publisher (particularly one wanting to introduce XML into a workflow before page composition) or for an archive with requirements to regularize content, the advantages of subsetting can be substantial. Use of a subset can reduce the complexity and costs of tool customization, quality assurance testing, and document manipulation. Subsetting eliminates unimportant and meaningless variation, which can make all work with a tag set more difficult. Processing can become faster and cheaper with a good subset whether an organization is editing XML by hand, working with a conversion vendor, or creating rich web applications.
A subset does not change the ability to interchange. Documents tagged to a subset of a JATS Tag Set are fully conformant to the Tag Set and generally indistinguishable from documents tagged using the complete Tag Set.
The following quote, from a user of the Publishing Tag Set, provides a user perspective for the claims this paper has been making. The JATS user, IngentaConnect™, is a commercial service providing journal articles over the web. According to their own website, they are the “world’s largest resource for scholarly publications” representing more than 250 publishers, being seen by over 25 million users, and storing and serving in excess of four and a half million articles.
Their website says: [bold emphasis mine]:
IngentaConnect’s standard DTD for provision and distribution of header metadata is a modified version of the NLM DTDs. We chose to use the NLM DTD because it is a widely-adopted industry standard which we hope should be readily suppliable and receivable by our partners. We chose to modify it because certain elements within it were not appropriate for use within the IngentaConnect™ context.
By adopting an industry standard, we minimize data conversion requirements at our end and yours; by modifying it (only slightly!), we ensure that it is fully able to provide quality data to us.
- 1.
- IngentaConnect™ Supplying article header metadata in IngentaConnect’s standard DTD. IngentaConnect™ website/ http://uploads
.ingentaconnect .com/docs/dtd/; October 6, 2010 .
- Why Create a Subset of a Public Tag Set - Journal Article Tag Suite Conference (...Why Create a Subset of a Public Tag Set - Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010
Your browsing activity is empty.
Activity recording is turned off.
See more...