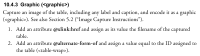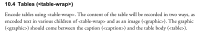Generating valid XML from journal articles requires careful workflow planning between multiple departments and typesetting vendors and/or customized software. However, that is only the first part of the battle to owning your content markup. How do you manage to generate consistently styled XML according to a journal’s style guide, as well as catch those pesky errors that invariably pop up upon uploading the files online? A closer look at the implementation of Schematron into an organization’s XML workflow will provide answers to these questions.
Monthly error reports, comprising a total of 8 months, were consulted and reviewed to determine systemic errors in the generation of XML content. Data was pulled from issue delivery errors that resulted from uploading files to the online host provider. Typesetter encoding guidelines were also consulted to generate rules to ensure content markup was consistent across articles and journals. The Schematron file runs during the ingestion process in the Content Management System and uses roles to indicate if the report has an error or may have one, thereby issuing a warning. Files with errors will not be sent to the online host provider until they are corrected; warnings can be overridden in order to send the files through.
After implementation of Schematron into the workflow, the majority of XML content markup problems are caught before the files are sent to the online host provider. This provides significant time and cost savings. The Schematron is considered a living document and rules are added on an as-needed basis, making it an integral part of the XML workflow.
Introduction
SAGE Publications is the world’s fifth largest journals publisher. Our portfolio includes more than 645 journals spanning the Humanities, Social Sciences, Science, Technology, and Medicine, and more than 280 are published on behalf of 225 learned societies and institutions. All of our journals are available electronically on the award-winning SAGE Journals platform powered by HighWire Press.
Historically, SAGE published journals using a back converted proprietary DTD before transitioning the complete corpus of journals to an XML first workflow. The transition was completed in November of 2010. Our typesetters shifted to this workflow, using the NLM Journal Publishing Tag Set Version 2.3. Issue files are deposited into our Content Management System and then delivered to HighWire Press for online production. No quality assurance of the XML, other than DTD validation errors, was performed prior to delivery to HighWire Press. Files would often fail upon delivery to the submission system; troubleshooting, correcting, and re-delivery were commonplace.
Collection of Data to Form Basis of Schematron Rules
There are a variety of ways to build Schematron rules. We developed an inductive approach by basing our rules off of two types of data. First, we gathered common typesetter errors. Second, we wrote rules based on our typesetter encoding guidelines. The following will outline the process and show some examples of specific rules.
1. Issue Error Reports
During our transition to the XML first workflow and the NLM version 2.3 DTD, we began to keep track of the number of deliveries per issue to HighWire Press. In total, 8 months of data was collected, based on issue error reports downloaded from HighWire Press. Corrections that were sent to the typesetters were analyzed and errors that occurred multiple times were logged. Some errors were as simple as having an email address that contained whitespace, to some as complex as a footnote being incorrectly encoded as an author-note. These errors were used to form the basis of rules for the Schematron.
Below are examples of some common errors and the Schematron rule which was written to catch them.
Example 1: Check validity of email addresses (<email>).
There is a whitespace after the <email> tag and before the v in the below email address:
This will fail on HighWire Press because the email is not valid. The whitespace should be placed before the <email> tag. In order to catch this error we use the following Schematron rule:
<p>Check that the email address does not contain whitespace.</p>
<rule context="email">
<report test="contains(.,' ')" role="error">The email address "<value-of select="."/>" contains space. Email addresses cannot contain whitespace.</report>
</rule>
Example 2. Check for article notes encoded incorrectly as author notes.
The below author note contains a footnote identifying supplementary material. This footnote is related to the article as a whole and not the author, therefore the placement of the footnote is incorrect and it should be moved to a footnote group.
<author-notes>
<corresp id="corresp1-0022034511408427">
<label>*</label>
<email>[email protected]</email>
</corresp>
<fn fn-type="supplementary-material">
<p>Supplemental material is available at www.sagepub.com<p>
</fn>
</author-notes>
Below is the Schematron rule which will catch this error:
<rule context="author-notes/fn">
<assert test="@fn-type = 'com' or @fn-type = 'con' or @fn-type = 'current-aff' or @fn-type = 'deceased' or @fn-type = 'equal' or @fn-type = 'other' or @fn-type = 'present-address'">There is an author note (article-meta/author-notes/fn) of type "<value-of select="@fn-type"/>". This is not a valid type value for author notes.</assert>
</rule>
Example 3. Check for a missing list type attribute.
While it is valid to have an element of <list> without a list-type attribute, HighWire Press will not accept this and a re-supply will be necessary.
<list id="list1-0010414011428596">
<list-item><p><italic>Hypothesis 1</italic>: ...</p></list-item>
<list-item><p><italic>Hypothesis 2</italic>: ...</p></list-item>
</list>
The below rule was written to catch this type of error:
<rule context="list" role="error">
<assert test="@list-type">A list must contain a type attribute value (one of: order, bullet, alpha-lower, alpha-upper, roman-lower, roman-upper, simple)</assert>
<assert test="(@list-type ='order') or (@list-type ='bullet') or (@list-type ='alpha-lower') or (@list-type ='alpha-upper') or (@list-type ='roman-lower') or (@list-type ='roman-upper') or (@list-type ='simple')">A list type value must be one of expected: order, bullet, alpha-lower, alpha-upper, roman-lower, roman-upper, simple.</assert>
</rule>
2. Typesetter Encoding Guidelines
In addition to gathering data from common typesetter errors, we also consulted our typesetter encoding guidelines in order to write rules based off of our encoding specifications to ensure that we receive uniform XML from our typesetters.
Some of the typesetter encoding guidelines with the associated rules are shown as examples below.
Example 4. Check for correct table graphic tagging.
illustrates that a table must contain an alternate graphic and the alternate-form-of attribute must be used.
Table Graphic Encoding Instructions.
The below rule was written to ensure that an alternate-form-of attribute has been added to the table graphic:
<rule context="table-wrap/graphic" role="error">
<assert test="@alternate-form-of">A table graphic must have an alternate-form-of attribute.</assert>
</rule>
Example 5. Verify that related article tagging is correct.
illustrates the encoding guidelines to follow when a related-article element is required, for instance, an erratum will need a related-article tag to ensure the correction will be linked back to the original article.
Related-Article Encoding Instructions.
The below rule was written to ensure that a related-article element contains the necessary attribute information so that the article can be linked back to the original article it is referring to.
<rule context="related-article">
<assert test="(@xlink:href and @ext-link-type eq 'doi') or (@page and @vol)" role="error">A related article (related-article) must have either a DOI xlink:href) or a volume (@vol) and first page (@page) combination.</assert>
</rule>
Example 6. Check that a graphical version of the table has been provided and that it follows the XML table markup.
shows that a table graphic is required and details the placement of the element.
Table-Wrap Encoding Instructions.
The below rule was written to make sure that a graphical version of the table has been provided and that it follows the XML table markup as specified in the encoding guidelines.
<rule context="table-wrap/table">
<assert test="preceding-sibling::graphic" role="error">The table wrapper (table-wrap) with @id "<value-of select="parent::table-wrap/@id"/>" does not have an alternate graphic (graphic) between the caption and the table body.</assert>
</rule>
Content Management System
Once we finished the development of the Schematron file, we configured it for use in our content management system (CMS). This section will outline the ingestion workflows of the CMS where we employ the use of Phases in our Schematron, as well as describe how the use of Roles better helps us manage our content.
Ingestion Workflow
When we started building our Schematron, it was determined that we would need a number of different Schematron files for the various types of content our CMS handled. However, instead of creating separate Schematron files, we incorporated the use of Phases. Phases can be used within a Schematron file in order to group sets of patterns so that only a specific set of rules are checked against a particular type of content. This way, only one Schematron file is needed for the CMS system which makes updates, corrections, and version control much simpler.
XML files are ingested into our CMS via different workflows based off of the type of content. That content is then checked against a corresponding Schematron Phase. shows the type of content and the corresponding Schematron Phase.
The Phases in were created specifically for the type of content they are checking.
Example 7: Check publication dates for current issue content.
The current issue content phase has additional rules to check the publication dates (the below example checks for a current year). Since some current content can come in a bit late, or a bit early, variables are set to allow for current year, last year, or next year only.
<rule context="/article/front/article-meta">
<assert test="number(pub-date[@pub-type='epub-ppub']/year) = year-from-date(current-date()) or number(pub-date/year) = (year-from-date(current-date()) + 1) or number(pub-date/year) = (year-from-date(current-date()) - 1) or number(pub-date/year) = (year-from-date(current-date()) - 2)" The publication year (pub-date[@pub-type='epub-ppub']/year) is "<value-of select="pub-date[@pub-type='epub-ppub']/year"/>". It should be the current year (<value-of select="year-from-date(current-date())"/>), last year, or next year.</assert>
</rule>
Example 8: Check volume/issue element existence.
The online first content phase has a rule to check for the existence of a volume or issue element, which should not be present in publish ahead of print content.
<rule context="article/front/article-meta" role="error">
<assert test="not(exists(./volume))">OnlineFirst content should not contain a volume element (<volume><value-of select="./volume"/></volume>).</assert>
<assert test="not(exists(./issue))">OnlineFirst content should not contain an issue element (<issue><value-of select="./issue"/></issue>).</assert>
</rule>
The archive content phase contains less stringent rules due to the nature of back conversion. Also, month and year values are not checked due to the varied publication history that exists with back content.
Use of Roles
Many rules as they are written can output a false positive. We developed our Schematron with the use of roles. By using roles, we can either set a rule to report an error or a warning. If the Schematron report returns an error, the issue files will not be ingested into the CMS and will have to be corrected before the issue can move forward in the system. If the Schematron report returns a warning, the CMS will give the user an option to either accept the content as is and override the report, or to fail the content and require a correction and resubmission. Below are some examples of rules where we have set the role to be a warning instead of an error.
Example 9: Check for spaces within the contributor surname.
Many errors are made by incorrectly tagging a contributor name segmentation. Encoding of part of a given-name incorrectly as a surname requires a human eye to determine if an actual error exists:
<name>
<surname>Ella Smith</surname>
<given-names>Joanne</given-names>
</name>
The name “Ella” should be encoded as a given-name instead of the surname. Since this type of error requires some fact checking to determine if it is an actual error, we specify the role of the rule in the Schematron as a “warning”. The following rule addresses this:
<rule context="front/article-meta/contrib-group/contrib/name/surname">
<report test="contains(.,' ') and not(matches(.,'^(de|De|di|Di|van|Van|el|El|le|Le|van der|van den) '))" role="warning">The author surname "<value-of select="."/>" contains whitespace. Is this correct?</report>
</rule>
Since many surnames can contain multiple names with a whitespace, we built an exception into the rule for the most common multiple surnames so the rule won’t fire on a known surname with whitespace.
Example 10. Check for all caps in article title.
The below rule was written for journals that are presented in print with all capital letters, but the XML should be captured as initial caps. However, there are rare instances where the article title should be in all capital letters, so the role is set as "warning".
<rule context="article-meta/title-group/article-title">
<assert test=". eq '' or matches(.,'\p{Ll}')" role="warning">The article title ("<value-of select="."/>") appears to be in all capitals. Please check.</assert>
</rule>
Example 11. Check for "S" prefix on page numbers in issue supplements.
This rule checks that page numbers of a supplemental issue include the prefix S. However, not all of our journals use this format, so the role must be written as a “warning” and human intervention is needed to determine if the warning can be pushed through as is, or if a correction is required.
<rule context="front/article-meta/supplement">
<assert test="starts-with(following-sibling::fpage,'S')" role="warning">This appears to be a supplement but the first page value (<value-of select="following-sibling::fpage"/>) doesn't include the prefix "S".</assert>
<assert test="starts-with(following-sibling::lpage,'S')" role="warning">This appears to be a supplement but the last page value (<value-of select="following-sibling::lpage"/>) doesn't include the prefix "S".</assert>
</rule>
Example 12. Check use of sec and title instead of p and italic/bold formatting.
This rule checks for the incorrect use of font formatting (italic/bold) as opposed to using the <sec> and <title> elements in a structured abstract.
<rule context="*:abstract" role="warning">
<report test="count(*:p[bold[count(preceding-sibling::*)=0] or italic[count(preceding-sibling::*)=0]] ) > 1">The abstract contains italic or bold formatting, please verify this should not be structured with sec and title tagging instead.</report>
</rule>
The display of the section titles should be controlled by the online template and not by formatting within the XML. shows the PDF display, an example of incorrect XML, and an example of the correct XML. This rule, however, has the possibility of returning a false positive. For instance, an abstract could begin with a Latin species name and use of the <italic> tag would be necessary, so we have set the role to “warning”.
Abstract Encoding Samples. A: Example of structured abstract in PDF. B: Example of bad encoding, with use of <italic> element.
Cost/Time Savings
Putting Quality Assurance in the Typesetters’ Hands
As we developed the Schematron for our CMS, we also created a version of it for use by our typesetters. The typesetters built the use of our Schematron file as a step into their XML first workflow. Typesetters now check the XML they produce against the appropriate Schematron Phase prior to submitting the files to us. By instituting Schematron into the XML first workflow as close to the beginning of the process as possible, errors in content encoding are caught much sooner. This also shifts the quality assurance burden of the XML back to the typesetter. If they encounter errors, they must correct them prior to submission to our system. If warnings are generated in the Schematron reports, the typesetters must evaluate those warnings and determine if they can be ignored, or must be corrected. When there is a question regarding an error or warning, the typesetter is instructed to contact us prior to delivery of the files. The typesetter also benefits from seeing the error reports so that they can catch common problems and enhance their workflow to ensure that the errors do not occur in the first place.
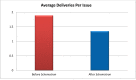
Reduction in Number of Deliveries Per Issue
Prior to the implementation of Schematron into our workflow, our average number of file deliveries to HighWire Press for an issue before online publication was 1.89. This means that, on average, issue files were sent to HighWire Press approximately two times before an issue could be published. The second delivery of files indicates that corrections were needed before the issue could be published. After implementation of Schematron, our average number of deliveries prior to publication fell to 1.35. This represents a 29% reduction in errors prior to online publication (see ). This is a significant reduction in the amount of times we have to resubmit an issue prior to approving it for online publication.
Average Number of Deliveries Per Issue.
Keeping our number of deliveries down allows us to keep our costs down in a number of ways. Besides the bottom line costs of online hosting, there are other less quantifiable, but significant savings.
Reducing the number of errors prior to the delivery of files greatly reduces staff time spent to log into the online submission system and troubleshoot the error. Issues with errors require production editors to have adequate XML expertise in order to identify the problems with the files, and then the ability to explain the correction needed to the typesetter. Since our typesetters are located in a different time zone, the correction will take a minimum of 24 hours to correct, but can often run into several days. Having our typesetters catch as many errors up front by building Schematron into their workflow not only reduces staff time, but also publication delays. It also minimizes the amount of XML expertise that is needed for production editors to perform their job.
Conclusion
Completing the hurdle to transition all of our content into an XML first workflow using the Journal Publishing Tag Suite version 2.3 was only the first step in the process to gain control of our XML content. Careful planning was necessary to evaluate common errors in our XML files in order to write Schematron rules that can catch those errors up front in the workflow. This enabled us to push the quality assurance of XML to the typesetters, takes the emphasis off of production editor intervention, and ultimately saves publication delays. Referencing journal encoding guidelines is also a necessary component to building a useful Schematron. This allows rules to be written to ensure that our implementation of the DTD is being employed for all XML files. Building Schematron phases into our CMS further allows us to ensure that the XML we deliver to our online host provider is free from systemic errors which helps us keep costs down, and reduces staff time and publication delays. Using Schematron can transform an XML workflow that is just getting by, to one that thrives and works for you.