

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2013 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2013.

While converting NLM book tag XML to an ePub seems like a relatively straightforward process (hey, an ePub is mostly just HTML, right?), setting up a workflow to do just that is quite challenging. It turns out writing the XSLT could be considered the "easy" part. Other problems, such as dealing with ePub display issues across ebook readers (anything from minor CSS differences to major MathML display problems), deciding what tagging makes the most sense semantically, and figuring out how to give semantic meaning to visual formatting such as table cell shading add a layer of complexity to the process. This paper discusses the challenges, rewards, and as-yet unresolved problems encountered in the process of creating an NLM to ePub3 workflow.
Introduction
CFA Institute: Who We Are
CFA Institute is the global association of investment professionals that sets the standard for professional excellence and credentials. The organization is a champion for ethical behavior in investment markets and a respected source of knowledge in the global financial community. The end goal of CFA Institute is to create an environment where investors’ interests come first, markets function at their best, and economies grow. CFA Institute has more than 113,000 members in 140 countries and territories, including 102,000 CFA charterholders, and 138 member societies.
ePubs: Why and How
Our organization has a number of book series published in an NLM 3.0 XML-first workflow, including a new study program designed to be interactive and mobile-friendly. In the interest of making this new study material flexible and as widely available as possible, we could not be limited by a print-first workflow and a print layout–based e-book. ePub3 was the obvious candidate. It is an open standard, it is accepted by many distribution channels, and it can contain rich media. The content resides in the ePub file as XHTML5, which makes it possible to create all the content files with XSLT.
Having already adopted NLM 3.0 for book content and MathML for equations, much of the infrastructure for an XSLT workflow was in place. The remaining task sounds simple: create an XSL workflow to transform XML to XHTML5. It turns out the actual process of writing the XSLT code is one of the easier tasks in this workflow. We did not want to lose the semantic tagging from our source XML inside our ePub files, which limited our ability to use many shortcuts or hacks to get the visual display of our ePubs exactly as intended. Other issues, such as reader fragmentation, further complicated matters.
An Overview of the ePub Format
The ePub standard is developed and maintained by the International Digital Publishing Forum (IDPF). The most recent version of the standard, ePub3, is a reflowable electronic publication format that allows publishers to use a single file for multiple electronic distribution channels. According to the IDPF, ePub3 “defines a means of representing, packaging and encoding structured and semantically enhanced Web content—including XHTML, CSS, SVG, images, and other resources—for distribution in a single-file format.” [http://idpf.org/epub]. The ePub format is accepted by many distribution channels, including iBooks, NOOK, Kobo, and Sony Reader. It can also be easily converted to Mobi for distribution through Amazon.
ePub Package Structure
As a self-contained publications package, an ePub file contains all styling and metadata information necessary to display the publication. The ePub package contains the following:1
- META-INF folder
- container.xml: This file identifies the root file for the ePub.
- OEBPS folder
- content.opf: This file contains metadata for the ePub package. This includes the title, author names, a file manifest, and the ePub “spine” (a list showing the order in which the files should appear).
- nav.xhtml: This is a navigation document that contains all headings in the ePub and is set up in an HTML list format.
- toc.ncx: This is a legacy navigation file. In ePub3 reading systems, this file is superseded by the nav.xhtml file, but it must be included for ePub2 backwards compatibility.
- Content files: The ePub content is included in the package as XHTML5 files that are styled with CSS. Images, videos, and audio files are also in the ePub package.
- mimetype file: This file declares the mimetype for the ePub package as application/epub+zip. When packaging the ePub, this file must be added to the zip file first.
The basic structure of an ePub package is shown in Figure 1. Note that this basic structure is the same for both ePub2 and ePub3 files.
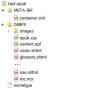
Fig. 1
ePub File Structure.
The Workflow
This ePub3 workflow uses an XSL transform to convert a book XML file into separate chapter XHTML5 files for inclusion in the ePub package. It also uses XSLT to create the ePub metadata and navigation files. A Perl script adds numbering to the legacy NCX file and an Adobe Illustrator script exports vector images to PNG for figures and MathML fallback images. Below is a brief overview of the workflow process:
- Creating metadata and navigation files: Several XSL transforms are run on the book XML file to create the navigation files (nav.html and toc.ncx) and the content.opf file. A Perl script is run on the toc.ncx file to fill in the sequential “play order” numbering that defines the ordering of the content documents.
- Creating chapter XHTML5 files: An XSL transform is run on the book XML file to split the XML into individual chapter files. The chapter files are then converted to XHTML5.
- Images: Figures and equation images are converted from vector EPS files to PNG files using an Adobe Illustrator script.
- Packaging the ePub: Currently, the ePub files are packaged manually. Gathering the files into the package is fairly quick using a prebuilt folder structure, but creating a script to gather and package the files is in the works as a future process improvement.
- Quality Control: After the ePub is packaged, the file is validated using the IDPF’s ePub validator tool, which can be found at http://validator.idpf.org/. The validator checks for many errors, including metadata, linking, and HTML markup problems. When the ePub file is confirmed valid, our internal Quality Control (QC) group makes a final check of the file.
After much testing and refining, this has proven to be a fast, reliable process for creating ePubs from XML.
Challenges and Solutions
Developing a workflow for creating ePub files poses quite a few technical and organizational challenges. The following sections discuss many of the challenges we encountered and what solution or workaround was used.
Choosing a version: ePub2 or ePub3?
In choosing which version of ePub to use for our book content, we found that ePub3 is the clear frontrunner. ePub3 has several advantages over ePub2, including
- rich media,
- interactivity, and
- endorsement by a wide spectrum of trade and standards organizations.
Our most recent textbook series is a dynamic, approachable course of study, and its study material needs to support that. The study material includes video, must be reflowable, and, in future iterations, will include more interactive elements. ePub2 does not support these requirements, and given that ePub3 is backwards compatible when fallbacks are included, ePub3 is the obvious choice.
Reader Fragmentation
One of the biggest challenges to creating ePubs is reader fragmentation. CSS rendering differs across reading systems and there’s a varying level of support for the ePub3 spec. Some readers handle ePub3 markup well, while others are not even able to link to HTML5 elements. To keep the process manageable, our goal is to come up with a single ePub file that works consistently across as many reading systems as possible. Having multiple ePub files of the same book for different reading systems makes the process onerous, especially when ePub files are being created in addition to other formats like print and web and each additional file variation requires its own QC review process. With enough research, testing, and tweaking, it’s possible to create an ePub file that works reliably across reading systems.
Unfortunately, because ePub3 support is not yet widespread or consistent, getting a single ePub file to work reliably across reading systems may mean excluding certain ePub3 features. Our textbooks are currently distributed through a vendor whose platform supports ePub3 features like MathML and HTML5 semantic tagging. But because our non-textbook publications are distributed through our publications site, we’re not able to target a specific reading system.
This means our non-textbook publications are set up to display reliably across reading systems, but they exclude certain ePub3 features. There are several reasons we chose to sacrifice newer features for the sake of reliability.
- We’re not able to produce, QC, and keep track of multiple ePub files for the same book.
- We want our content to be available to as many people as possible. Having a reading system not render the display properly or at all degrades that ability.
- If a user who is not familiar with the nuances of ePub reading system runs across a display problem in an ePub, he is likely to think there’s a problem with the book itself rather than the reading system, especially if the book is downloaded through a well-known platform. We’d rather not have to try to explain to users that the ePub is technically correct based on the spec but their reading system does not fully support it.
At some point in the future, after our first batch of textbooks have officially been produced through this workflow, we will revisit these reader issues and see if ePub3 support has improved or if we can come up with better workarounds.
Dealing with Reader Fragmentation in General
Before tackling the problem of reader fragmentation, it was necessary to familiarize myself with the ePub3 spec. EPUB 3 Best Practices, by Matt Garrish & Markus Gylling, is an excellent resource and contains much of the necessary information. The Book Industry Study Group maintains a chart showing which ePub features work on which reading systems; this chart can be found at http://www.bisg.org/what-we-do-12-152-epub-30-support-grid.php. The ePub3 specification document itself is also a useful reference, and it can be found at http://www.idpf.org/epub/30/spec/epub30-contentdocs.html.
In order to create ePubs that display reliably, it’s helpful to keep the formatting simple. The ability to keep things simple depends somewhat on the complexity of the content and on the ability of stakeholders to accept that the display of the ePub will not be perfect (or look exactly like the print version) in all cases. Below are some steps I’ve taken to reduce complexity:
- Stick to a linear layout and avoid using CSS floating elements. Until we’re able to incorporate responsive web technologies, this is an easy way to make sure an ePub will display relatively well across different screen sizes.
- Because the widths of list labels varies, use the @li attribute for <li> elements to set list labels and avoid customizing list hanging indents where possible. I found customizing list indents in CSS to be troublesome, especially considering the standard rendering looks fine as it is.
- Allow table widths and line breaks to be set by the reading system. This can be a difficult simplification to live with, especially when line breaks look much better in the print edition, but those kinds of typesetting tweaks are hard to do in a reflowable file.
Keeping the CSS simple and allowing the reading system to use default formatting allows for greater reliability. Even though this may involve making design compromises, it’s still possible to create ePubs that look good and work reliably across reading systems. We’ve incorporated many of the more important design elements from the print versions of our textbooks, including colors for headings and key terms, shading for boxed text, and banners for the chapter opener pages. Figures 2 through 7 show examples of print design elements that successfully transfer to ePub.

Fig. 2
Example of Box Shading in Print.

Fig. 3
Example of Box Shading in ePub.

Fig. 4
Example of Headings in Print.

Fig. 5
Example of Headings in ePub.

Fig. 6
Example of Chapter Opener Banner in Print.

Fig. 7
Example of Chapter Opener Banner in ePub.
Finally, the ePub should be tested on as many reading systems as possible. There are resources available for determining which ePub3 features work on which reading systems,2 but since reading systems both develop and devolve over time, these should be used to help set up the ePub and not as replacement for testing of actual content. I've tested the ePubs produced with the XSL workflow across a range of systems, including the following:
- iBooks
- Adobe® Digital Editions 2.0
- Kindle Fire, eInk (these are not technically ePub files but are converted to Mobi from ePub files using Amazon’s Kindle Previewer3 tool)
- Kobo eInk
- NOOK® eInk
- VitalSource Bookshelf®
One of the benefits of an XML/XSLT workflow is its consistency. Because the output HTML files are transformed to a reliable, predictable form every time, the most thorough functionality testing is done upfront when the workflow is being developed initially. After that, less rigorous testing is needed for ePubs created through this workflow.
Specific Reader Fragmentation Problems
The following sections detail specific reader fragmentation problems I’ve encountered and what, if any, solutions I’ve implemented.
ePub3 Backwards Compatibility
ePub3 is technically backwards compatible with ePub2, but some ePub3 features don’t work well or at all on ePub 2 readers.
- <figure> tag. The <figure> tag is a new HTML5 tag “that is self-contained” and “is typically referenced as a single unit from the main flow of the document” [HTML spec: http://dev.w3.org/html5/markup/figure.html]. The <figure> tag is useful for marking up exhibits, examples, other boxed text, and (of course) figures. Using the <figure> tag “makes it simpler for a reader to navigate and understand content, as it’s another impediment to the logical reading order removed” [Garrish and Gylling 250]. Unfortunately, some ePub readers simply can’t correctly display elements tagged with <figure> (based on my testing, this includes Adobe Digital Editions and NOOK). See Figures 8 and 9 for the Digital Editions and VitalSource Bookshelf rendering of a <figure> tag. Child elements such as inline images and tables are dropped, and in some cases the visual display is a mess. If it’s not possible to target a specific ePub platform for a certain book, I use a <div> tag instead of a <figure> tag. This is far from an ideal workaround because a <div> tag is semantically meaningless.Switching back and forth between using <div> and <figure> tags is handled in the transform. There’s a parameter in the XSL that specifies if I need an ePub2-friendly file (using <div>) or if the ePub can have full ePub3 support (using <figure>). This parameter is set in the transform scenario, and different scenarios are set up for different ePub requirements.
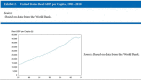
Fig. 8
Incorrect Rendering of a Figure Tag in Digital Editions.
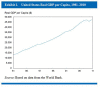
Fig. 9
Intented Rendering of a Figure Tag in VitalSource Bookshelf.
- <section> tag. Another HTML5 element that may not work properly in some readers is the <section> tag. The <section> element “represents a generic section of a document” [ePub spec http://www.w3.org/html/wg/drafts/html/master/sections.html#the-section-element] such as a chapter or a lower-level section. The display generally looks okay, but in my testing I’ve found that some reading systems are not able to follow a hyperlink that points to a <section> element. Because <sec> elements in our NLM content already have IDs, early versions of our XSL simply passed those IDs through to the HTML and the navigation files used those for linking. In this case, the solution is simple: create IDs for the section’s headings based on the <sec> ID and link to the heading instead.
- epub:switch element. The epub:switch element is supposed to allow us to include new features in ePubs and also include a fallback version for older readers. A good example of this is including MathML and an image of the equation. If the reader can’t render the MathML, it should display the image instead. However, some readers don’t make use of the epub:switch element, which makes it difficult to include newer features and retain backwards compatibility.In general, if a reading system can’t handle the switch element, it will display both the primary case and the default case. For MathML equations, that means a user will see an unformatted equation followed by an image of the same equation. In another non-ideal workaround, if we’re producing a non-textbook publication that’s not being distributed through a system which can render MathML and can handle the ePub:switch element, we only include math images.
- Navigation files. In order for an ePub3 file to validate with ePubcheck, it must include the legacy .NCX file. For the most part, this file is no more of a problem to create with XSL than the nav.html file is. However, it does mean there are two navigation files to check. Also, the NCX file requires a @playOrder attribute, which shows what order the navigation points should appear, and this must be sequential across all nested levels. The nesting makes adding this number with XSLT problematic, so we use XSL to create the NCX file and Perl to populate the @playOrder attribute.
Special Considerations for Kindle
While not technically an ePub3 file, Mobi files can be created from a valid ePub3 file using Amazon’s Kindle Previewer. In my experience, it’s very simple to convert ePub3 files to Mobi, and with this XSL workflow the conversion is generally error free. Given how simple it is to convert an ePub3 file to Mobi, this is an easy additional distribution channel for those who are already creating ePubs. There are a couple of things that can be done to improve the user experience.
- Define the TOC. For Mobi files, the table of contents file has to be defined in the content.opf file. It’s simply a matter of adding a <reference> element to the content.opf <guide> element:
<reference type="toc" title="Table of Contents" href="nav.xhtml" /> - Set the Initial Page View. I don’t want to get into the debate on where it’s appropriate to begin viewing an e-book (The cover? TOC? First page of chapter 1?), but I will point out that it’s possible to set the initial page view for Kindle by adding a <reference> element to the <guide> element in the content.opf file:
- <reference title="Start" type="text" href="chapter1.xhtml#CFA0001-h1"/>
When the initial view is set, it will open to that page the first time the book is opened. After that, it opens where the user left off.
eInk Device Limitations
We’ve encountered a reading system limitation during our testing — some eInk devices, like the NOOK and Kobo, won’t scroll a large table when the table is too large for the screen. Others, like the Kindle, can scroll large tables but split the table in between columns and display no indication that the table extends past the edge of the screen. If a reader can’t scroll a large table (or doesn’t know he needs to), he will miss out on information in part of the table. We’ve not come up with a suitable workaround for this and have had to add a disclaimer on our publications site noting that if an ePub is viewed on certain kinds of eInk devices, tables may be cut off.
Tables and Boxed Text
In the ePub3 workflow, boxed text elements are placed into the new HTML5 <figure> tag. According to the W3C spec [http://dev.w3.org/html5/markup/figure.html], the figure element “represents a unit of content [...] that is self-contained, that is typically referenced as a single unit from the main flow of the document, and that can be moved away from the main flow of the document without affecting the document’s meaning.” All boxed text in our content fits this description, so the <figure> tag is perfect.
Most tables in our content also fit the description of the <figure> tag, as they’re generally referred to by a table or exhibit number. Because numbered tables are called out in the text and linked, they don't necessarily have to be viewed right after the callout. In print, such tables could safely "float" to the next page. However, some tables need to remain inline with the text. So, any <table-wrap> with a <caption> or <label> element is generally referred to by name or number and is therefore placed in a <figure> tag. Any other table is left inline.
As for the coding of the tables themselves, they’re standard HTML tables with nested <thead> and <tbody> elements:
<figure>
<table>
<thead>...</thead>
<tbody>...</tbody>
</table>
<footer>...</footer>
</figure>
Tables in our XML use OASIS markup. When we were establishing our XML workflow, we originally chose a version of the NLM book DTD to include OASIS table markup, not the (standard) XHTML table markup the NLM DTD includes out of the box. We chose OASIS because it allowed greater flexibility for table markup than XHTML does. But this means there is an additional conversion back to XHTML for inclusion in the ePub.
When transforming from XML, tables are split up by <tgroup> elements. The reasoning behind this split is that if there’s a row mid-table that’s tagged as a column head, it makes sense from an accessibility standpoint for it to be placed in its own <thead> group. Consider the following XML:
<table-wrap>
<oasis:table>
<oasis:tgroup>
<oasis:thead>
<oasis:row>
<oasis:entry>Part A</oasis:entry>
</oasis:row>
</oasis:thead>
<oasis:tbody>...</oasis:tbody>
</oasis:tgroup>
<oasis:tgroup>
<oasis:thead>
<oasis:row>
<oasis:entry>Part B</oasis:entry>
</oasis:row>
</oasis:thead>
<oasis:tbody>...</oasis:tbody>
</oasis:tgroup>
</oasis:table>
</table-wrap>
The preceding XML is split by <tgroup> and will transform into the following HTML markup:
<figure>
<table>
<thead>
<tr>
<th>Part A</th>
</tr>
</thead>
<tbody>...</tbody>
</table>
<table>
<thead>
<tr>
<th>Part B</th>
</tr>
</thead>
<tbody>...</tbody>
</table>
</figure>
If there’s more than one row in a heading, it should be placed in a <thead> element. It’s acceptable to forgo the <thead> element for single row headings, but it’s simpler in the XSL transform code to always add the <thead> element and split by <tgroup>.
As for table notes, if the table is placed in a <figure> element, table notes are placed in a <footer> element at the end of the <figure> element. If a table gets split by <tgroup>, the table notes should still apply to everything in the <table-wrap>. By placing the notes in a <footer> element, it’s clear semantically that the table notes apply to the entire <figure> element. Otherwise, it’s likely the table notes would need to be duplicated so it is clear that they apply to both tables.
For inline tables (those that don’t appear in a <figure> element), using a <footer> is not an option because <footer> would apply to the parent section, not the table. In these cases, table notes are placed in a <tfoot> element. In our content, there’s little chance inline tables will have multiple <tgroup> elements, so the chance of having to duplicate a note is small.
Boxed Text Nesting and Large Tables
In our content, <boxed-text> elements are nested inside other <boxed-text> elements quite often. Fortunately, it’s acceptable based on the W3C spec to nest <figure> elements inside <figure> elements. Permitted content includes flow content,4 and <figure> tags are considered flow content. Generally, what we have are “example” boxes with nested “exhibit” boxes (these exhibits can be either nested <boxed-text>, <fig>, or <table-wrap> elements), and these nested exhibits are appropriate for the <figure> element (as discussed above).
Getting the semantic meaning of the nested boxes correct is theoretically simple thanks to the <figure> tag, but support for this tag varies across reading systems. Sometimes element positioning and formatting is a mess, and some reading systems drop child elements.5 Because we can’t accept having content missing for some users based on their reading system, the <figure> tag is replaced with a <div> tag for anything we’re not distributing through a known system.
The visual display for nested boxes and large tables can be problematic whether they are in a <figure> or <div> tag. In an attempt to keep the ePub as simple, flexible, and reflowable as possible, the layout of these elements is generally left up to the reading system with a few rules in the CSS. First, margins for nested box elements are set so the nesting hierarchy is clear visually. Second, to help with the display of large tables in <figure> elements, a max width is set for paragraphs inside <figure> tags. In some reading systems, if a table is too large and has to scroll, the text inside the parent <figure> also scrolls, which makes it awkward to read the text. Setting a max width prevents this.
Semantics
The introduction of improved tagging in HTML5 makes it possible to create semantically rich ePub files. Creating semantically rich e-books makes it easier for users to discover and consume content. Improved semantics allows reading systems to create better visual displays that wouldn’t be possible otherwise, and semantically tagged files generally display more consistently across reading systems. Creating ePub3 files that make use of semantic HTML5 tagging, however, is more involved than creating ePub2 files. The following sections discuss the challenges I’ve come across and the solutions I’ve used to overcome these problems.
Sections versus divs
New HTML5 sectioning tags and type attributes are used to create consistent, structured HTML files that are easier to use with assistive technologies. These tags can replace generic <div> tags and classes. Of course, including this semantic tagging adds a layer of complexity to creating HTML files.
The good news is that the needed structure already exists in the NLM XML files and simply needs to be converted to HTML5 markup. The not-so-good news is that some semantic tagging needs to be considered carefully before being used to ensure that it’s being used properly. And the bad news is that there are semantic tagging possibilities we’re exploiting in NLM XML that don’t exist in HTML5.
ePub Document Structure
According to the W3C HTML5 specification,6 primary structural content which “would be listed explicitly in the document’s outline” should be enclosed in the new HTML5 <section> tag, and we have limited each section to have only one heading. It turns out the sectioning structure in our NLM XML maps almost directly to this required HTML structure. Below is an example of an XML section and an HTML section.
NLM XML
<sec id=“0014-s01 sec-type=“intro”> <label>1</label> <title>Introduction</title> <p>...</p> </sec>
ePub3 HTML
<section epub:type=“subchapter” id=“0014-s01”> <h1 id=“0014-s01-h1”>1. Introduction</h1> <p>...</p> </section>
The higher level structure does not map quite as closely, but is still close enough to make the transformation very simple:
NLM XML
<book-part>
<book-part-meta>
<title-group>Chapter Title</title-group>
</book-part-meta>
<body>...</body>
</book-part>
ePub3 HTML
<body>
<article epub:type="chapter">
<header>
<h1>Chapter Title</h1>
</header>
<section>...</section>
</article>
</body>
The article tag (shown above) is another new HTML5 tag. According to the W3C spec [http://www.w3.org/TR/html5/sections.html#the-article-element], the “article element represents a complete, or self-contained, composition in a document.” Because the chapters can make sense on their own, separate from the whole book, the article tag is used here to wrap the book chapter.
Math
According to the specification document [http://www.w3.org/TR/MathML3/], “MathML is an XML application for describing mathematical notation and capturing both its structure and content.” Using MathML thus allows us to retain the semantic meaning of equations in text while improving their visual display in an ePub. Including MathML, however, poses several challenges. First, there’s the matter of tagging equations in MathML and integrating that markup in the XML. MathML is complex and would be tedious to mark up manually in any volume. Fortunately, there are several equation editors that allow users to lay out equations visually and export that layout into MathML. In our case, we use MathType which integrates with our systems to create XML with MathML in place.
Second, finding a reading system that renders MathML is difficult. Based on my research and testing, many reading systems have limited to no support for MathML rendering. iBooks renders MathML, but only a limited subset, which is not helpful for more complex equations. Based on a 2010 W3C MathML implementation study (which is admittedly ancient in the rapidly advancing ePub world), iBooks is only able to render 7% of Presentation MathML [http://www.w3.org/Math/testsuite/results/tests.html]. The rendering should be improved on iOS 6+ devices, but as of this writing we have not tested on anything but iOS 5. And as mentioned above, some reading systems are not able to use the <epub:switch> element,7 which is used to set up an image fallback for MathML equations (generally, both the fallback image and the unformatted MathML appear).
Not having a reliable fallback system makes it almost impossible to include MathML in an ePub without targeting a specific reading system. Some systems use MathJax8 to render MathML (based on the W3C MathML study, MathJax is able to render 98% of Presentation MathML), and if these systems also support the epub:switch fallback, equation display can be handled relatively elegantly. Unfortunately, because the fallback switch is not reliably supported, the publications we distribute through our website don’t include MathML, only images. This is far from ideal, but until ePub reading systems improve this method allows us to provide consistent ePub files.
For textbooks that include MathML, we are in the process of checking MathML display very carefully, as we don’t want MathML rendering or markup problems to introduce errors. We’ve encountered several MathML rendering quirks and markup errors so far.
- Comma separator. When large numbers use commas as thousands separators, the comma is marked up in the <mo> operator tag, which includes operator, fence, accent, or separator characters.9 The MathML rendering engine adds space on either side of the <mo> based on its content. When it contains an operator, space is added on both sides. When it contains a separator, the surrounding space is suppressed but only the left side. For example, one thousand renders as 1, 000 by default.This spacing may work for commas inside sentence text, but looks odd as a thousands separator. To solve this, I added a rule in the XSLT to look for <mo>,</mo> and add a @rspace="0" attribute, which removes the space from the right side of the element. There is a chance this will remove space after a comma if it’s used in sentence text and is marked up in the <mo> tag. However, the danger seems slight and we’ve yet to run across a problem.
- Aligning on the equal sign. One limitation in MathJax is that it doesn’t support aligning equations using the <maligngroup> and <malignmark> elements [https://groups.google.com/forum/#!topic/mathjax-users/x_cKEMVL240]. Because these are the elements that MathType uses to show alignment in the MathML, any equation we had that we aligned on the equal sign was appearing as centered in the ePub rendering. As a workaround, our equations are set to left align with the XSL transform. It does not look as good as aligning on the equal sign, but it is preferable to centered equations. Figures 10 and 11 show examples of the current ePub rendering with left alignment and the preferred alignment on the equal sign from the print version.
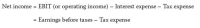
Fig. 10
Aligning on the Equal Sign in Print.
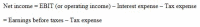
Fig. 11
Aligning on the Equal Sign in ePub .
- Currency Symbols. MathType tags currency symbols separately using the <mi> identifier tag, which is used to tag variables and constants. A dollar sign would appear as <mi>$</mi>. According to the spec, when an <mi> tag contains only one character, that character should be italicized, and that’s how it’s rendered by MathJax. Since it looks odd to have an italicized dollar sign on a number that’s not italicized, I’ve included an XSL template to check for currency symbols in <mi> tags and suppress the italic formatting by adding a @mathvariant="normal" attribute. There’s a chance here that if we have an equation in bold that also includes currency symbols, those symbols will not appear in bold (@mathvariant="normal" removes both italic and bold formatting). But, again, the danger seems very remote and we’ve yet to run across a problem.
- Overscript caret symbol. When the caret symbol is used as an overscript, MathType exports the character to the MathML as a literal character instead of using its Unicode value. This was solved by simply swapping out the caret with its Unicode with an XSL character map.
Considering how apprehensive we were about including MathML in our ePubs, it has actually turned out fairly well. The issues introduced by MathType and MathJax have generally been minor formatting issues that are not incorrect, just inconsistent with how the equation displays in print. The more serious issues have been caused by tagging errors, not by the reading system.
Semantic Tag Usage
Certain semantic tags require research to make sure they are being used properly. Some tags like <blockquote> are a little more complicated than they sound. Some seem more complicated than they need to be; <em> and <strong> tags are still used and <b> and <i> tags have been brought back with semantic meaning. And, as useful as the epub:type attribute is, its scope is too narrow to support some content types that appear in textbooks.
Local Formatting
In HTML5, the <b> and <i> tags are back and now have semantic meaning. These now exist in addition to the <strong> and <em> elements. Below are the element definitions from the W3C:10
- <b>: The b element represents a span of text offset from its surrounding content without conveying any extra emphasis or importance and for which the conventional typographic presentation is bold text; for example, keywords in a document abstract or product names in a review.
- <strong>: The strong element represents a span of text with strong importance.
- <i>: The i element represents a span of text offset from its surrounding content without conveying any extra emphasis or importance and for which the conventional typographic presentation is italic text; for example, a taxonomic designation, a technical term, an idiomatic phrase from another language, a thought, or a ship name.
- <em>: The em element represents a span of text with emphatic stress.
Adding this markup presents a couple of issues. First, figuring out which tag is appropriate can be difficult and subjective. Different authors and editors may have different ideas on what should be called out as important and what should only be different stylistically. Second, NLM markup only has bold and italic tagging. It's not possible to transform to two different elements without additional information in the XML, so we use <b> and <i> throughout.
epub:type Attribute
The epub:type attribute is used to identify the type of content in <section> elements or other elements such as <aside>. For example, the section containing the chapter content can be marked up as <section epub:type="chapter">, and an aside containing a footnote can be marked up as <aside epub:type="footnote">. The full list and definitions of these section types is provided by the IDPF’s ePub3 Structural Semantics Vocabulary [http://www.idpf.org/epub/vocab/structure/].
This vocabulary is extensive, but there are some section types in our content that are difficult to tag based on these definitions. Here are a few examples from our content:
- Learning Outcome Statements: Each chapter in our textbooks starts with a Learning Outcome Statement, which is a list of concepts the reader should know by the end of the chapter. It’s unclear which, if any, epub:type is appropriate. Is it an introduction? The vocabulary defines introduction as, “A section in the beginning of the work, typically introducing the reader to the scope or nature of the work's content.” That may be appropriate, but some of our content has an actual introduction section immediately following the learning outcome statement.Currently, our content has this tagged as a generic subsection of the chapter section. While not incorrect, this is a very specific type of section that could be improved semantically with its own epub:type.
- How to Use: Each textbook volume includes a front matter section that explains how to use the volume, how it’s structured, and other explanatory information about the curriculum. Like we found with Learning Outcome Statements, there are a few options in the Structural Semantics Vocabulary which will work but are not exact.
- Problems and Solutions: Most chapters include review questions at the end of the chapter. There is an epub:type="practice", but according to the vocabulary this attribute should be used on <aside> elements. The practice problems are set up in list form and aren’t contained in <aside> tags. So, currently, the problems and solutions sections are simply tagged as epub:type=“backmatter”.
The problem is figuring out which existing epub:type best fits the content while not overthinking and overcomplicating the markup. For example, does a Learning Outcome Statement really need its own epub:type? It is possible to define a custom epub:type, but it’s unclear how some reading systems would handle these.
<figure> Tag
As discussed above, the <figure> tag is new to HTML5 and is used to mark up figures, tables, and boxed text. This element takes some research to figure out where it’s appropriate in our content, but is not overly complicated. The main issue is figuring out what elements can be read outside the main flow of content. This is appropriate for figures and boxed text in our content in almost all cases, but as noted previously, tables are tricky.
HTML5 Semantic Tagging Shortcomings
Even with the expanded semantic tagging in HTML5, certain types of content don’t have appropriate tags in the tagset. Below are several instances I’ve come across.
Optional content
Some of our textbooks have content that is optional. The optional content is included because some users may find it useful, but it does not appear in the review questions or on the exam. This optional content poses a couple of challenges. First, and not surprisingly, I’ve not found any markup to denote what content is optional and can be skipped. Second, users of the print and ePub need to have access to the same information. If a user of the ePub doesn’t know some content can be skipped, he is at a disadvantage.
Lacking any semantic tagging, we decided the display of optional content in the ePub should mirror the display in the print as closely as possible. In print, the start of optional content is marked with a flag in the margin with the text “Begin Optional Content” and the end is marked with an ending flag. Both flags are joined by a dashed rule. The setup in the ePub is very similar (minus the joining rule). The flags are styled so they stand out appear inline with the content. Figures 12 and 13 show how these flags appear in print and ePub.

Fig. 12
Print Optional Content Flag.

Fig. 13
ePub Optional Content Flag.
Equation Labels
Another content type that is lacking an appropriate semantic tag is labels for numbered equations. In print, these labels appear as a number inside a colored box and are placed to the right of the equation. This might work visually in an ePub, but in some reading systems the label number could easily be confused as part of the equation itself. To solve this, the equation is changed to read “Equation #” and is placed above the equation inline with the text.
Reference and Author Name Tagging
References and author names have very detailed markup in the NLM book DTD. The upper level of the references section can be tagged with an epub:type and author names are pulled into the ePub metadata. But in HTML5, the tagging is far less granular — and thus, less semantically meaningful — than it is in the NLM book DTD.
Outstanding Issues
Our ePub workflow produces files that are a considerable improvement over print-based e-books from a usability perspective. However, there are several ways we could further improve our ePub files:
- Decimal alignment. The first thing on the wish list is figuring out how to align columns in tables on the decimal point. This is done in all of our content in print and it makes number-heavy tables easier to read. As far as I can tell, this kind of alignment either can’t be done in CSS or isn’t supported in ePub. It may be possible with JavaScript, but that’s not widely supported by ePub readers.
- Print page numbers. While it seems like an unnecessary throwback to a previous era, it will be helpful for some users if actual print page numbers are included in the ePub file. It is obviously easiest to retain print page numbers if the print and ePub are created from the same workflow. In our case, two different workflows are used, but if users are studying the same material using both print and ePub, it’s helpful to have a common point of reference. Also, some reading systems use the page numbers if a user wants to print from the ePub.The problem here is to figure out how to export some kind of page number list from the print file that can be automatically imported into the HTML using a script. My original idea was to come up with an InDesign script to export a page list, and then use some kind of text matching to add those page numbers to the HTML. It sounds easy in theory. But since InDesign is print layout it shows UTF entities as literal characters (even in the scripting toolkit), so any kind of text matching is problematic. Figure placement would also cause issues with this method.
- Math testing. When our equations were set up in MathType, we focused on making the visual display of the equation correct for print. MathML was not a concern at the time; our print workflow uses the EPS files exported from MathType, not the MathML. Some of the tweaks made to adjust the visual display are exposed by MathML rendering with MathJax. For example, I’ve noticed cases where an equation doesn’t display correctly because lines have been broken to fit a print column. It will look okay as an EPS image, but the MathML can get distorted.Considering how many MathML equations are in our content and how complex they are, a considerable commitment of time and resources will be required to test, tweak, and retest all equations.
- Better semantic tagging in tables. Tables in our ePubs are only partially semantically tagged at this point, so there are a couple of improvements that can be made.
- It’s possible to associate a table cell with its header cells using the @headers attribute on the table cell (<td>) element. There are several challenges we have to deal with before we can add this markup. First, our content currently has no tagging showing which cells are row headers (only column headers). Once this information is in place, the XSL transform will need to be updated to generate @id attributes for table head (<th>) elements and matched with the @headers attribute on the <td> elements.
- Certain tables in our content have visual formatting that affects the meaning of the tables. For example, accounting tables use single line bottom rules to denote addition and double line bottom rules to denote summation. In our content, these are set up as cell borders. Currently, we have no method of signifying the meaning of these cell borders other than visually:
- Another issue is cell shading. This is less likely to affect the actual meaning, but there are some cases in which shaded cells are called out for additional consideration:The question is, how do we give semantic meaning to this formatting? Is it possible with the tagging or will it require a content rewrite?
- Full workflow automation. It’s my dream to be able to provide source data to a script and have it transform the XML, export images, package files, and hand back an ePub file. This would make it easy for anyone with the correct software to create ePubs, and it would keep me from forgetting certain steps. Since going through each step of the process doesn’t take long compared to the time commitment it would take to implement full automation, this dream remains a low priority.
Benefits of Using ePub3 and an XSL Workflow
Dealing with the various ePub3 issues can be challenging, but it’s worth doing because an ePub3 creates a better experience for all users. Creating semantically rich content makes it easier for users to discover and consume content. It also allows reading systems to create better visuals displays that wouldn’t be possible otherwise. By creating ePub3 files, we hope to have the ability to present our content to as many readers as possible.
Using an XSL workflow to transform NLM XML to ePub3 provides several advantages:
- Consistency. Because no manual markup work or tweaking is being done to the ePub3 files, they are consistent across publications. As long as the XML tagging is consistent, the ePub3 files will be consistent. Also, because these files are not based on the print layout, formatting quirks and unnecessary style overrides from the print books don’t make it into the ePub file. This consistency also helps with functionality testing. Because the output is consistent and reliable, most of the functionality testing can be done upfront.
- Reliability. Now that our XSL workflow is set up and tested, it produces valid ePubs every time. In my experience, exporting ePubs from print layout programs can be flaky and unreliable. Different books using the same template can experience different behavior; one will export well (though will likely still need manual tweaking after export), while another will crash the layout program without any explanation other than a generic crash message. I’ve encountered no such “mystery errors” in the XSL workflow.
- Speed and Flexibility. After a book is compiled into a volume XML file, creating an ePub with this workflow is quite fast. It usually takes around 15 minutes to create an ePub, and that includes exporting vector images to PNG.
Also, because this workflow was developed in house and is maintained by CFA Institute employees, any changes can be made and tested quickly. New W3C recommendations or new ideas on ways to improve our products can be implemented almost immediately.
Footnotes
- *
For a more thorough discussion of the ePub package file, see EPUB 3 Best Practices by Matt Garrish and Markus Gylling, available from the publisher here: http://shop
.oreilly.com /product/0636920024897.do. - **
See the BISG’s ePub3 Support Grid here: http://www
.bisg.org/what-we-do-12-152-epub-30-support-grid .php. - ***
This tool is available here: http://www
.amazon.com/gp/feature .html?ie =UTF8&docId=1000765261. - ****
According to the W3C HTML5 specification document, “most elements that are used in the body of documents and applications are categorized as flow content.” [http://www
.w3.org/TR /2011/WD-html5-20110525/content-models .html#flow-content-0] - *****
For more information, see the “Reader Fragmentation” section above.
- ******
Information about sections in the W3C HTML5 spec is available here: http://www
.w3.org/TR/html5/sections .html#the-section-element. - *******
According to the Book Industry Study Group’s ePub3 Support Grid, iBooks and Kindle both support the <epub:switch> element, though I have not been able to successfully implement the switch in either reading system. The ePub3 Support Grid is available here: http://www
.bisg.org/what-we-do-12-152-epub-30-support-grid .php. - ********
MathJax is an open source JavaScript library that renders MathML as scalable, reflowable text in web browsers and ePub readers. According to the W3C MathML study, MathJax is able to render 98% of Presentation MathML [see http://www
.w3.org/Math /testsuite/results/tests.html]. For more information see http://www .mathjax.org/. - *********
The full MathML spec is available here: http://www
.w3.org/TR/MathML2/chapter3 .html#presm.mo. I also found the tutorial MathML Presentation Markup for the Impatient helpful for getting started in MathML. It can be found here: http://www .xmlmind.com/tutorials/MathML/. - **********
The element definitions are available here: http://www
.w3.org/TR /html-markup/Overview.html.
- The Challenges and Benefits of Automating NLM-to-ePub3 File Conversion - Journal...The Challenges and Benefits of Automating NLM-to-ePub3 File Conversion - Journal Article Tag Suite Conference (JATS-Con) Proceedings 2013
Your browsing activity is empty.
Activity recording is turned off.
See more...