Many objects published in a codex format in print do not easily translate as
"books" online. After adopting BITS as its core model for traditional book
content, Silverchair has created an initiative to leverage the same tag library
and expand its implementation to load other book-like objects, non-standard
content objects, and born-digital content onto a shared platform.
This paper is a case study of how BITS was adapted for our system to encode a
library of defined "types" of non-standard content.
What we call a book in the print world can mean very different things in a digital
format. Setting aside the usual variations in structure, many objects we call
"books" have such fundamentally different needs in terms of design and interface
that they resist standardization.
At the risk of venturing into highly theoretical terrain, the task of defining what
constitutes a digital “book” is an essential first step in preparing a digital
platform to represent such objects. Indeed, it also frames a system for identifying
outliers to that definition. In the print world, books are generally described as
printed paper bound together along a spine. They have chapters that may be organized
into larger, thematic, Parts, and they tend to come with some front and back matter,
such as forewords, tables of contents and indices. The importance of representing
that paratextual matter in an online version depends upon the context of the
resource’s intended use or audience: some publishers are invested in archival
representations of their content and preserving every single aspect of the printed
resource in its online version. Others are focused on delivering the body of the
content to the user, with limited amounts of historical data translated online. For
example, all of the books currently hosted on Silverchair’s SCM6 platform have their
Tables of Contents dynamically generated based on the structure of the XML. But
older editions of those same books, if they were they to be saved for posterity in a
resource like the Digital Public Library of America, might be more strictly
described according to the original print resource. No matter how close the
translation from print to digital, however, I must note that a digital book is not
and cannot be the same thing as a “codex.” There will always be aspects of print
resources that are not easily remediated for consumption on a screen. For example,
note the grey indicators on the pages of the American Academy of Pediatrics’ Red
Book, which serve to help the reader target the “Section” of the book they need (Fig. 1).
These are extremely helpful in the context of a busy doctor’s office, but useless as
special markers encoded in an XML file. And then there are other reference books,
such as exam prep guides, encyclopedias, and point-of-care references defy the
organizational logic I outlined above. Finally, we cannot forget the emerging genre
of born-digital content: it was never intended to be bound by covers, but often
retains the structures and formatting of its print ancestors. For our clients, it
was becoming important that their online host be flexible enough to accommodate all
of these variations in content. For our own purposes, it was essential that we do so
on a shared platform, in the most efficient and standardized method possible.
For Silverchair, the difference between a “book” and non-standard content objects
boils down to differences in metadata and general user experience. A standard “TOC”
page consists of the familiar thematic and hierarchical organization that
accompanies a (generally) sequential reading experience. Although there may be
variations in how that information is structured (Parts / Chapters / Sections), a
standardized page template can be used to represent that material by default.
Likewise, a standardized content display page can be employed to enable reading the
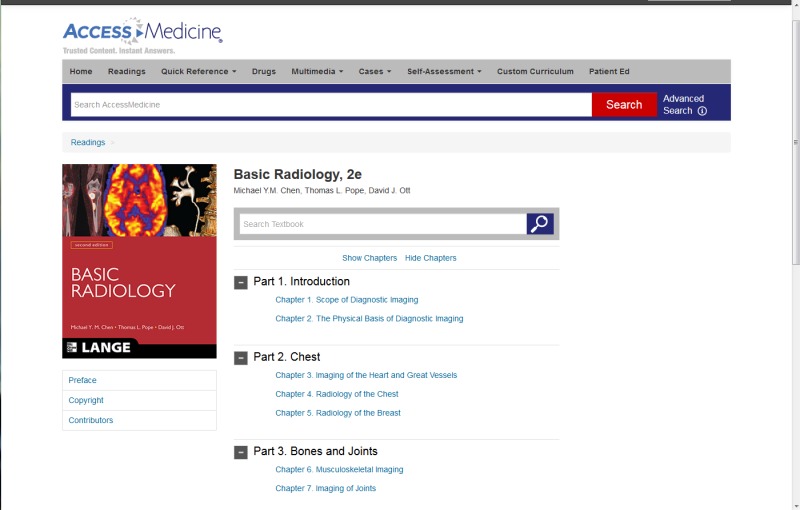
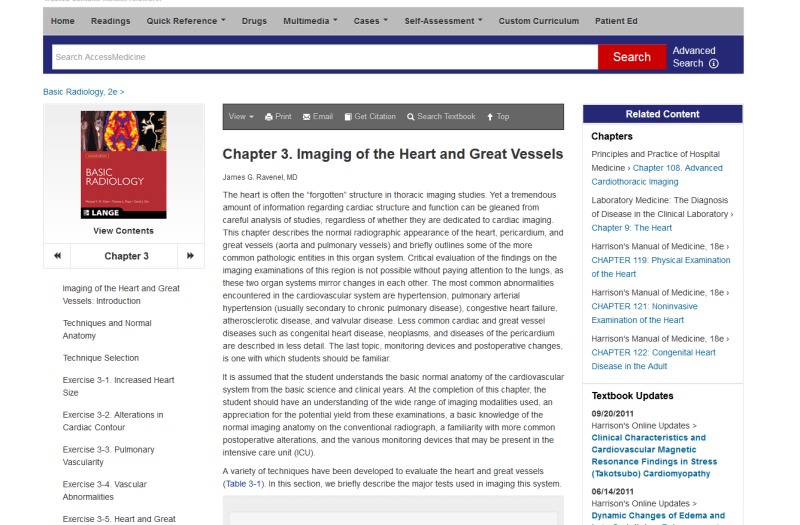
body of the document. Across our platform, Silverchair hosts over 1200 books, many
of which fall neatly into a similar template to the one shown in Figure 2.
Conversely, non-standard content has much more substantial browsing information, and
requires a more modular organizational strategy. There were three main criteria
considered:
Does the object have different browse needs or does it require a
sophisticated landing page?
Are there requirements around how the material is displayed, shown in search,
or reported in analytics that differ from existing book templates?
Is the content actually ancillary textual material to a book or journal
resource?
Take, for example, a glossary. Glossaries can be bound as individual resources of
their own, or they can be included as back matter for larger book resources. In one
scenario, we had a client in need of a mostly-book oriented site, but also wished to
include a glossary feature that would serve as a reference for all the books on the
site, but maintained separately from the actual book XML. In the course of
fulfilling these requirements for one client, we sought a solution that could be
applicable to many others on our platform.
Taking into account some variation in requirements and design elements across clients
and across sites, a glossary still has a predictable structure for which a template
can be built. Looking at the roadmap of other projects for the year, our analysts
began to amass a library of other non-standard content types like the glossary, and
we worked to outline the particular requirements of each of those ‘types’– from XML
to display. We referred to them all as “generic buckets of sections,” or, in acronym
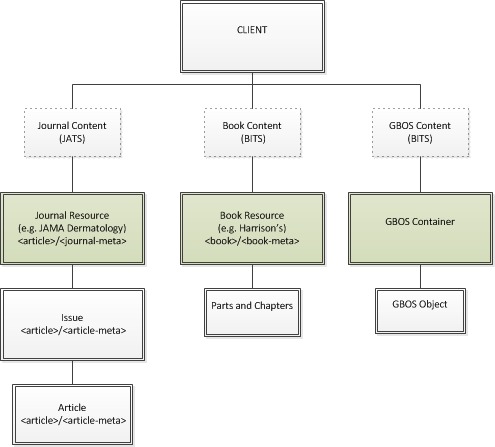
form, GBOS. GBOS objects, such as glossary entries, could then be assembled into
GBOS Containers, which might refer to an original print resource, a product, or some
other more general organizing principal. This generic container is the equivalent of
a book or journal in our database.
It is at this point that we can descend from the lofty heights of theory and site
architecture to consider textual encoding, and how the non-standard, or GBOS,
approach dove-tails with XML requirements. Without dwelling too much on the history
of content at Silverchair, it is worth noting that the company began as a provider
of highly customized individual sites. Content-wise, this meant that we dealt with
numerous proprietary DTDs that were managed by our clients, or created internally
based on the specific needs of each site. With the launch of the SCM6 platform
(originally developed for journal –oriented content) the utility of implementing a
common standard across clients became clear, and we adopted JATS (the “blue” tag
set, for Journal Publishing) as the common language for journals and proceedings.
When we expanded SCM6 to include book content in 2013, BITS was a logical choice for
a common tag library: because it built upon existing JATS elements, it allowed us to
expand SCM6’s capabilities incrementally, rather than starting all over with
something new.
Even as the first BITS-encoded book went live on SCM6 in January 2014, it was
becoming apparent that our client’s needs were quickly evolving beyond journal and
book content. The GBOS model offered us a library of ‘types’ to focus on, but no
matter how unique the needs of each GBOS type might appear to be, we did not want an
encoding solution that was highly customized or proprietary. It was essential that
we continue on our trajectory of standardizing our content approach in such a way
that it would still be straightforward for vendors and clients without deviating too
far from accepted libraries and standards.
We formed an initiative to investigate the best way forward, with the goal of
determining how best to use BITS for GBOS content. It was clear that we did not want
to craft anything brand-new, and folding in some other tag library could be
prohibitively expensive. After all, many of the resources that seemed to fall into
the category of non-standard content already had lives in print as books. If there
were a way to used BITS – which was already quite useful for describing those common
features – then progress could be made rapidly.
In the end, two approaches were evaluated: 1) extend BITS to include more generic
elements that could be shared across non-standard objects, or 2) work within the
current BITS library and change the meanings of some existing elements based on a
content-type declaration in the XML.
At first, extending BITS to have a generic root element, <document> was
attractive. As a solution, it was intellectually tidy, and allowed our tools an
immediate method for differentiating content types in the XML:
<journal> for JATS, <book> for BITS, and
<document> for GBOS. However, such an ambitious initiative was
resource-intensive, required significant updates to our content management and
loading tools, and necessitated a deviation from the BITS as a tag library. The
preliminary documentation required to get our clients and vendors up to speed on our
own extensions was one challenge – constantly staying in sync as BITS evolved on a
parallel track seemed a potential hazard.
The second option involved adapting existing BITS elements and structures to fit GBOS
as well as books. This strategy would require no new elements to be added – only
some new attributes and new rules governing those elements – and we would be able to
stay in touch with BITS as a tag library. However, because we do import XML into a
shared relational database, there was some risk identified in having the same
element mean different things depending upon content type.
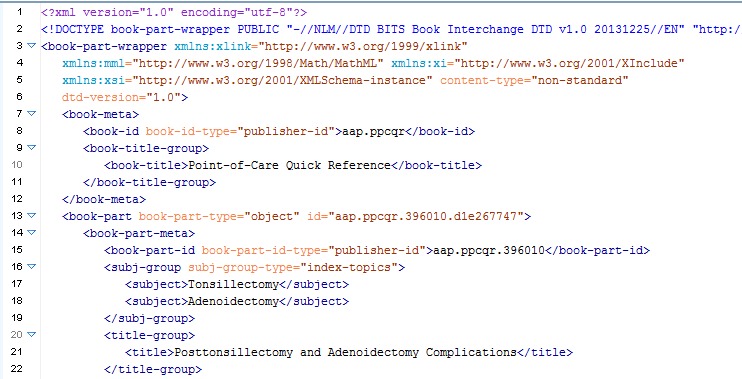
In the end, we chose to implement the second option. Figure 6 shows the metadata
elements for a point-of-care topic card in the American Academy of Pediatrics’
Point-of-Care Quick Reference. The <book-part-wrapper> element serves
as the root element for this GBOS object, with a now-required “content-type”
attribute specifying this as GBOS not book content. The <book-meta>
element is streamlined to include only two required elements: a <book-id> and
<book-title>. These values determine the GBOS Container (or organizing
principle) for this object. It is the first <book-part> element in
this file that contains metadata about the GBOS object itself (note the required
book-part-type=”object” attribute), including Publisher ID, DOI (if there were one)
subject group information, title, publication history, et cetera. Whereas a glossary
entry might be succinct, (requiring one <sec> element at most) a
point-of-care topic card such as the one shown here could be much more complex,
requiring further "chapters" or other main divisions within the GBOS. Another
required attribute was set aside for <book-part> in GBOS objects:
content-type="main-division" flagged important headers in the content, so that they
could potentially serve a unique function in display. From this level down in the
XML tagging, the elements are all exactly the same between books and GBOS.
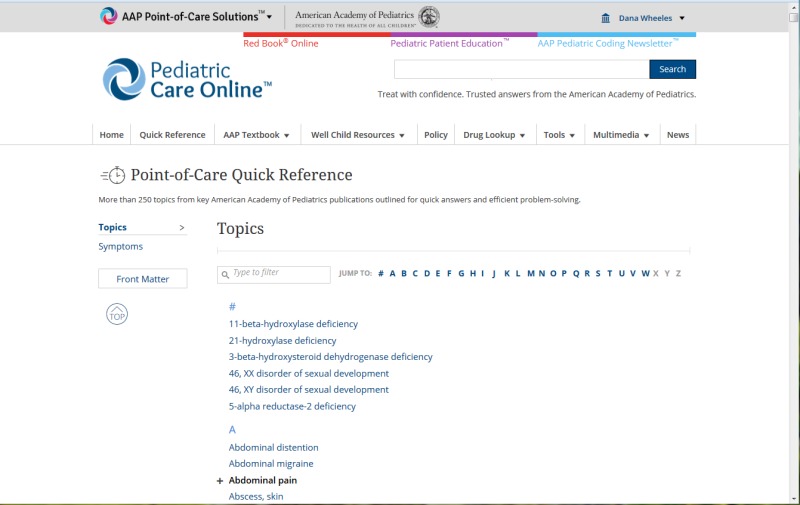
The next two figures illustrate how this XML is displayed on the site. The “table of
contents” is actually an A-Z browse feature powered by client-submitted subjects.
These are organized by two main categories: Topics and Symptoms, with the list of
links in the main column being semantic equivalents (or, in the XML,
<subj-group> values) rather than the titles of the GBOS objects
themselves. Note also that this particular GBOS Container has Front Matter
associated with it, which indicates just how closely books and GBOS can align
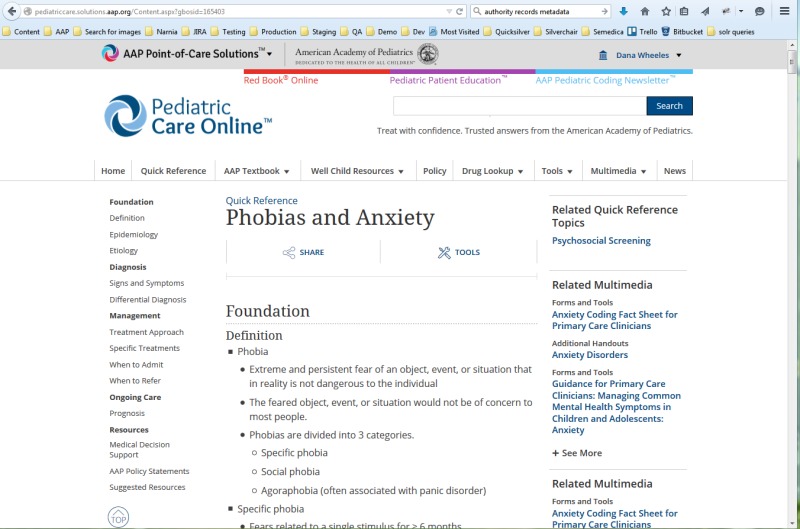
structurally. If you click through the “Agoraphobia” link on the landing page, the
system takes the user to the “Phobias and Anxieties” topic which looks quite
book-like. The column on the left offers jump-links to the “main divisions” and
section titles within the document for quick navigation.
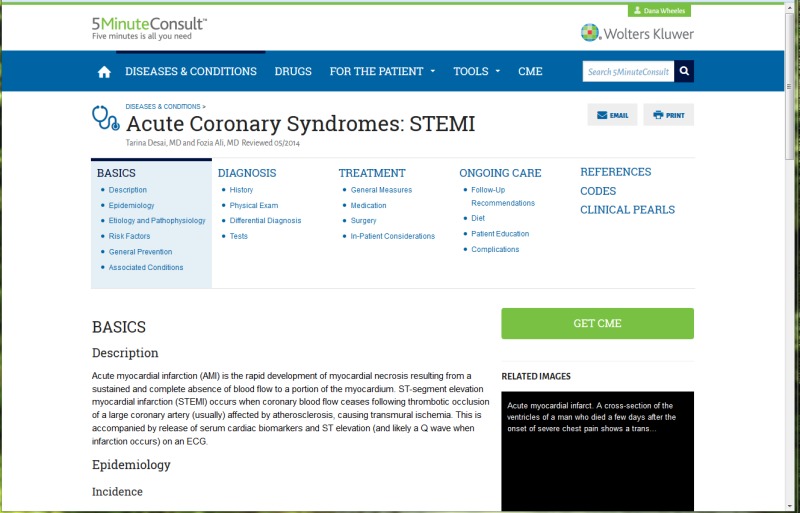
I’d also like to show you another object with the same GBOS type (point-of-care topic
card) from a different site, to give you a sense of the flexibility of the encoding.
This topic card from Wolters Kluwer’s 5 Minute Consult is structured almost
identically to the previous slide on the XML level – but many of the components have
been re-arranged.
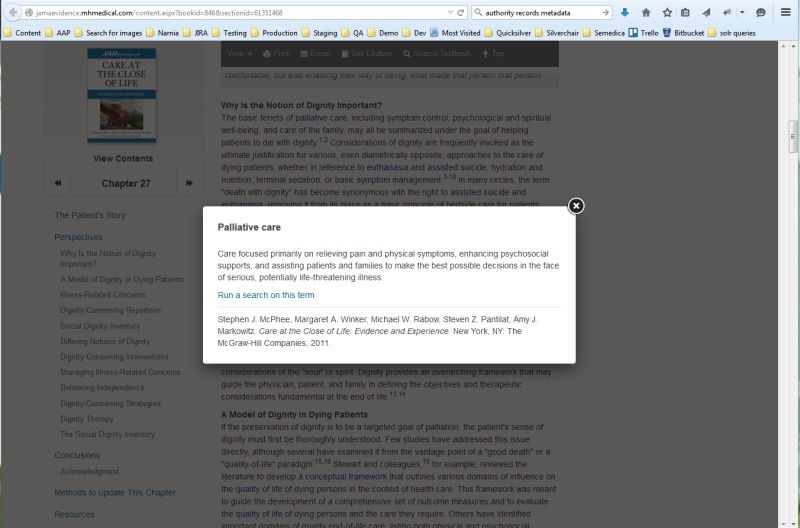
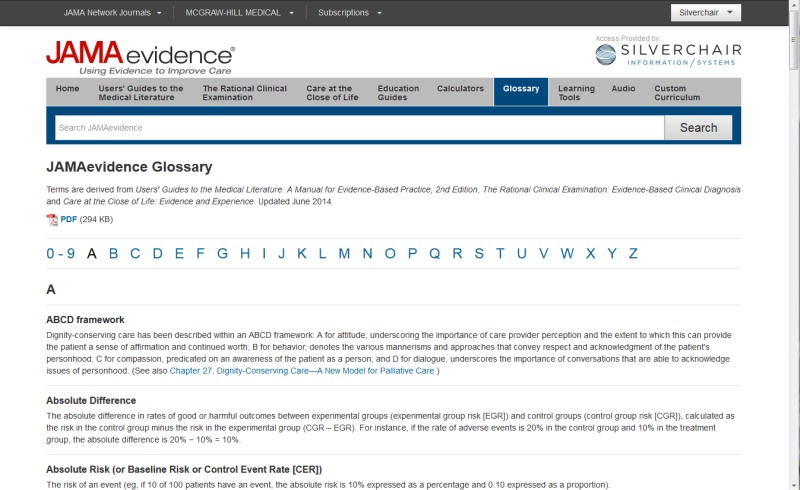
There are other GBOS types, however, that are not so book-like. To revisit the
example I gave at the beginning of my talk, a glossary can be structured similarly
in the XML, but act very differently on the site. In this image, the user has
clicked a link to a glossary entry within the text of a book, which opens a modal
displaying the contents of that object. Elsewhere on the site, a user could also
access this information from the GBOS Container, or landing page for the full
glossary. Each of these entries is an individual GBOS object (and, coincidentally,
an individual XML file), but they are assembled in a simple A-Z browse, driven by
title. By now the XML structure will look familiar: GBOS Container declarations in
the <book-meta> element, glossary entry specifics (including
<related-object> links to relevant book chapters) in the
<book-part book-part-type="object"> element, and the short body of the
entry itself in the <body> element.
On a practical level, when we receive XML for these two, very different non-standard
content types (the point-of-care topic and the glossary entry) we are able to
leverage most of the same XSLTs we use for book loading, and the same basic tool
framework. The only aspect of GBOS content loading that is not as dynamic as that of
books is the original creation of the GBOS Container. These are not made on the fly,
but are mapped out in the beginning of a project with content analysts, designers
and developers working in partnership with the client to identify the non-standard
content needs of a given site. GBOS is relatively new to our system, however, and as
our library of GBOS types and display widgets grows, we anticipate streamlining and
expediting this process. As of March 2015 we have a dozen GBOS Containers on the
SCM6 platform, and we are learning more about how non-standard content interacts
with our platform every day.
The digital realm is where non-standard content can really shine – interactions that
were clumsy in print can be engineered online in ways that enhance a user’s
experience. Alternately, many aspects of the print world are deeply embedded in our
conception – and encoding – of that content for online use. Throughout the process
of researching GBOS, and as we sought to continue using BITS to represent those
documents in our system, again and again I returned to the concept of the
skeuomorph – a design feature or structure that was useful at one
point in an object’s history, but is retained long past its necessity. Think of a
digital calendar designed to look like one you might hang on a wall, a smart phone
that reproduces the rotary experience of dialing, or faux-wood grain on a station
wagon. Using the <book> and <book-part-wrapper> elements
to wrap content that is not a book is definitely a holdover from the print world.
But for our case, I believe that we have managed to make the skeuomorph work to our
advantage. However inaccurate the adaptation may seem at first glance, using BITS
for non-standard content allowed Silverchair more functionality and flexibility in
content remediation and display, in a fraction of the time it would have taken to
conceive a completely new model. It is a solution that fits this interesting
intermediary period in scholarly publishing, in which we inhabit both the print and
digital worlds, and the two are inextricably connected.