XSweet, a toolkit under development by the Coko Foundation, takes a novel approach to data conversion from .docx (MS Word) data. Instead of trying to produce a correct and full-fledged representation of the source data in a canonical form such as JATS, XSweet attempts a less ambitious task: to produce a faithful rendering of a Word document's appearance (conceived of as a "typescript"), translated into a vernacular HTML/CSS. It is interesting what comes out from such a process, and what doesn't. And while the results are barely adequate for reviewing in your browser, they might be "good enough to improve" using other applications.
One such application would produce JATS. Indeed it might be easier to produce clean, descriptive JATS or BITS from such HTML, than to wrestle into shape whatever nominal JATS came back from a conversion processor that aimed to do more. This idea is tested with a real-world example.
XSweet - representing Word typescripts in HTML
XSweet is a project underway since August 2016 sponsored by the Collaborative Knowledge Foundation. Intended to run in conjuction with other components of an online data ecosystem, XSweet is all-open-source and distributed on Gitlab. It takes the form of a library of XSLT stylesheets to be run in sequence over nominally HTML5 data (while well-formed i.e. XML syntax) – starting with a transformation that extracts HTML from MS Word (docx format). XSweet includes filters and components that can be used not only for the extraction but for associated activities as well, "grooming" the data for use in downstream applications especially editorial applications.
Experience has shown that conversion from Word data is difficult to perform, at least at high quality with any consistency. Much as authors labor over documents in MS Word, any "random Word document" turns out, regrettably, as often as not to be lamentably far from ready for ingest into any system much less a publishing system. As specialists in document conversion know, sometimes we are lucky; too often, the gap is very wide between the way data is encoded and represented inside Word, and the kind of abstract descriptive format, in a legible plain-text based syntax, one would want for one's data, whether for publication or long-term archiving and access. (Such as a NISO JATS-based format.)
This may be somewhat puzzling if you remember Word documents now use an XML-based format. Since the release of Word 2007 (so, not even very recently), a Word document has consisted of a collection of files, mostly XML, collected together in a zip file and named .docx. Such a package may be decompressed using the standard zip protocol and its XML contents examined and processed. In principle, this should make Word documents tractable within an XML-based processing stack - the kind of toolset with which, as XML developers, JATS developers may be familiar with. (Such as XSLT and its companion technologies.) However, it turns out that even getting the data plainly legible in a Word document - when one reads it on screen or prints it - into even a rudimentary markup format, is rather harder than it looks, even using state-of-the-art tools. Complexities abound at every level. A rough breakout of issues appears in Appendix A.
By design, XSweet performs an "end run" around many of the problems. It approaches the challenge by redefining it: instead of solving the problem of "Word to X" (where X is JATS or your format of choice) it instead transmutes it into a problem of "HTML to X". For whatever reasons (interesting but beyond the scope of this paper), even if such HTML may be as semantically impoverished and inconsistent as the Word – it may be a big advantage to have it.
Thus XSweet takes on a single task: to represent, in HTML using a vernacular reasonably familiar to developers, text (document contents) "as it is given" in/by a Word document. Intriguingly this means that instead of trying to address harder problems (such as inferring structures or content types), XSweet can aspire to transmit with some fidelity any information that might later help resolve hard questions; and this is judged a net positive whatever the result. For purposes of later work, it is arguably better to show "what was there" in a rough-and-ready notation - especially when that notation – here HTML, and unlike the Word source data – is legible and intelligible.
The assumption, that is, is that subsequent conversion and improvement over inputs is not only necessary, but a good thing. In view of this (and our reliance on next steps in the process), the initial extraction is required first and foremost to expose what is given in the Word.
What XSweet does
- Processes XML from unbundled docx input.(Unzipping the docx file is left to the calling utility. This is so the transformation pipeline has no dependencies outside a series of calls on SaxonHE. For testing in XProc environments, a shell that reads docx without unzipping it, and transforms the contents, is provided using XProc.)
- Producing a "vernacular" HTML
- Familiar format!
- Presentational encoding since/when that's "what the author put there"
- We already have browsers and toolkits
- Produces (wf) XML (i.e. tractable for further processing)While the "actual semantics" are neither fully exposed, nor consistently represented – thus leaving us with significant work in data enhancement – yet we have lost nothing. And in HTML, the information we do have, presentational and haphazard though it is, is legible and accessible for further improvement.
What it doesn't do
- Produce "publication ready" results unassisted
- Make even an attempt at several necessary chores
- Metadata
- Citations and any other implicit linking(Explicit linking in WordML is weak)
- Figures, more complex "content objects"
HTML Typescript
The idea underlying XSweet is that HTML (or a variety or application of HTML) is a viable carrier format for progressive (human and machine-assisted) upconversion. "HTML Typescript" is the metaphor we use to explain this (the idea originated in correspondence between Adam Hyde and this author): the idea is that to exploit the networked digital environment for production – to put these tools to uuse – we need a data format that performs the role that paper typescript (that is, typed paper, or carbon copies or photocopies thereof) does (or used to) in paper-based information economies. Paper typescript works, in some ways, because as a channel, its expressive capabilities – limited though they are – are well understood by parties to communication – who know and respect, as well, the various ways one may go "out of band" to get one's message across. In this sense, typescript is a technology made to be hacked – and we need the same for the web. (Moreover, this is to complement more disciplined applications of electronic text such as JATS-based systems may be.)
Adam Hyde brought me the insight that in a web-based ecosystem, the question must always first be why is format and lingua franca is not HTML. This time, to this obvious question, it turns out, the usual answers regarding the superiority of a well-governed and relatively rational organization such as is exemplified (in the mind's eye) by one's favorite sort of XML (JATS, TEI or other as it may be), simply do not apply. By definition we are talking about a data format suitable for the carriage of uncontrolled data. The fact that HTML (at least unsupplemented by other rule sets) may, in and of itself, be notoriously hard to control, presents no concern from this point of view. Indeed the fact that HTML is already widely abused, makes it even better for our purpose.
Then too when it comes to formatting the contents of Word documents, HTML has a couple of signal advantages. HTML turns out to be a "good fit" for transformation target from Word, both in its strength (flexible, easy to abuse, escape hatches) and its weakness (it doesn't enforce structure or naming rules over content type names or classes, but falls back on presentational semantics). Where we have Word Styles – which are sometimes but not always unambiguous indicators of semantics in the data – we can make HTML "class" attributes with labels. Where we have presentational semantics, we can use CSS. Following a few simple rules, we can filter and rewrite these properties to clarify and disambiguate. While for these purposes, HTML/CSS is quirky and not what one might design for the purpose – it is also flexible, and its quirks are well understood and widely tolerated.
The amazing thing is how well this works. The HTML delivered by XSweet can be opened in a browser and it does indeed look much like the Word document. Perhaps even more importantly, features encoded into the original document are represented as-is, in such a way that further work – when those features present themselves systematically, as they often do – can be done to enhance and improve the data from there. For example, if the Word document author happens to have used a style "Emphasis", an HTML class attribute will turn up with this value, just in the correct places.
This leads to the second part of the project, the test to see how much if anything XSweet's "boosts" our ability to get all the way into BITS format.
From XSweet to JATS: the final ascent
This project took shape as an exercise by the author in testing XSweet, which was very freshly minted toward the end of 2016. As lead developer of XSweet, I was confident that the code was producing results as intended (at least up to some meaningful point). I was less confident that the HTML that came out was, indeed, both rich and correct enough (with respect to capturing "what was there") to handle an actual manuscript in (at least something closer to) "actual" production.
My solution to this was to conceive an end-to-end mockup of a publishing process, beginning with an author's manuscript in "raw Word" and culminating in NLM BITS (kindred format to NISO JATS). "Culminating", perhaps, but not concluding, since (wearing another hat, as a BITS developer), I knew that next steps would include the sorts of products one could make from the sort of well-controlled XML I intended to produce.
The text I identified was a manuscript monograph authored by a friend who kindly offered me permission to use (and publish) the text for these demonstrations. Thanks are owed to Mark Scott for making this part of the experiment possible.
The resulting work, Epigram Microphone may be seen at Pause Press, a project of Mark Richardson, Wendell Piez and Mark Scott. It is available in several formats. (Apologies are probably due to readers with actual design sensibilities, who can see none of us is a talented web designer. But the point of the project is not to demonstrate design, exactly, so much as potential – so while apologies may be due, none are offered here.)
The project followed the form of a mini editorial process: I took the Word docx file sent me by the author, and pushed it through XSweet to produce an HTML file. This artifact I then inspected in detail, proceeding to develop XSLT (some of which, indeed, already existed on my system in various forms) which converts the HTML Typescript into JATS (actually NCBI BITS format). The idea was, that once in BITS, everything else would be possible, inasmuch as processing JATS/BITS is something we know how to do.
And indeed this proved to be the case. The few hours it took me to produce BITS from the docx original, that was both faithful (as far as it went) and also "better" (for further editing and application), were minimal in comparison to the time we were then able to spend on things that really mattered – on editing and on determining all the details of publishing.
Made available with this paper is a package of XML representing intermediate stages of processing of this text – from extraction using XSweet, to post-processing, analysis and enhancement until a valid BITS document was in hand, good enough to continue editing.
By the time I was finished editing and developing production stylesheets (as we came close to being able to flip the switch, the author came back to me with some pages of edits), I was pleased to say that XSweet was indeed good enough for the job.
This isn't to say that there were not challenges. However the basic approach does seem to have been vindicated: even if an automated extractor for Word cannot be trusted to give us something at all finished, its output may still be useful. For those purposes indeed HTML Typescript proved capable, inasmuch as it provided all the hooks needed to convert (this data, at least) into "proper JATS", with content types intact. This was possible precisely due to XSweet's stance of "represent everything potentially relevant, but do not interpret any of it". The fact that it was represented using familiar syntax was in itself enough.
Since that was exactly the plan – and since, as it proved, XSweet was able to produce "good enough" results to support next steps – the effort was judged a success.
Gory details (HTML Typescript → BITS)
Mapping Mark's typescript into a BITS document presented challenges on several fronts:
- StructureWhile the Word document was (as expected) flat - a sequence of paragraphs with no grouping or organization - Mark's monograph had sections with headers. The simplest solution here was to hand-code a "scaffold" document and "siphon" the Word document content into the sections so demarcated. HTML, conveniently, has no provision to discourage or encourage either a sectioned or an unsectioned document - so this could be done before conversion to BITS.
- EpigramsFor the most part, Epigram Microphone is a straight sequence of paragraphs, albeit with nested quotes (as befits an academic monograph) and occasionally, implicit (untitled) sections. However, there are also sections of epigrams - brief snippets of prose (one or two short paragraphs), which require special handling.In JATS/BITS, the best fit for these was judged to be the statement element. In conversion from the Word, extra line feeds (resulting in empty paragraphs in conversion) proved to be a sufficient indicator of these - making it possible to tag these, as well, based on features of the input as exposed by XSweet. In this case, since empty paragraphs have "forensic" value, it helps that XSweet does not dispose of them.
- There are other content objects including display quotes, and (on one occasion) a quote-within-a-quote. JATS/BITS tagging was fairly easy to apply to represent all these.
- As noted, in a couple of chapters, Epigram Microphone does have implicit (untitled) sectioning, as indicated by extra white space in the Word MS. Inasmuch as XSweet is able to capture this (incidental) information in its HTML, these clues, again, are not lost to subsequent steps. Not only vertical whitespace, but the presence of tabs and paragraph indents prove to be meaningful for purposes of determining the correct "logical" structure for this text.The clean BITS markup speaks for itself.
Somewhat amazingly, all these complexities were wrestled to the ground in a few hours of work. (Having capable tools is essential for this kind of work, but XSLT inside XProc proved up to the job.) Only when it became clear that nothing was left that could be dealt with programmatically, did I start to make edits. And the author started to make edits.
Fortunately by that point, we were maintaining the document in BITS, and edits (and subsequent production) were as easy as expected.
Before … and after
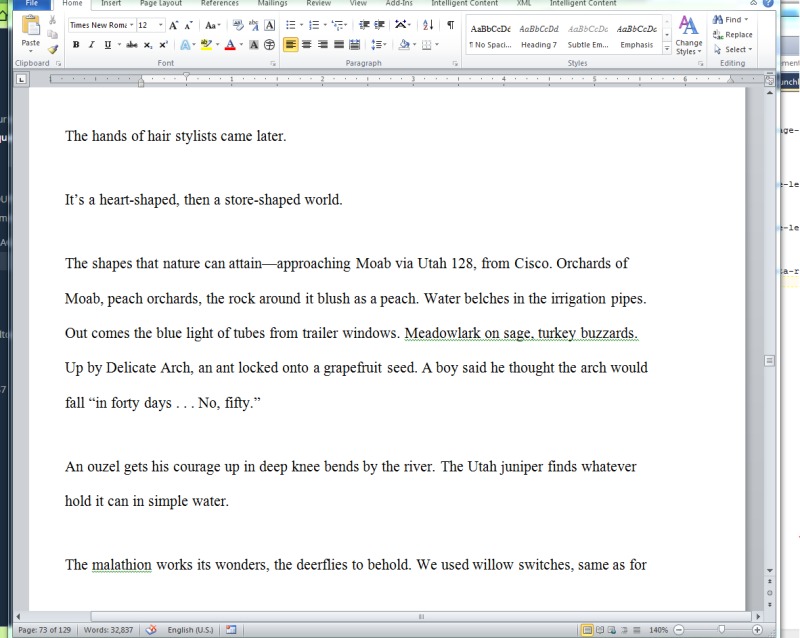
Fig. 1An MS, in Word ...

Fig. 2… HTML Typescript ...
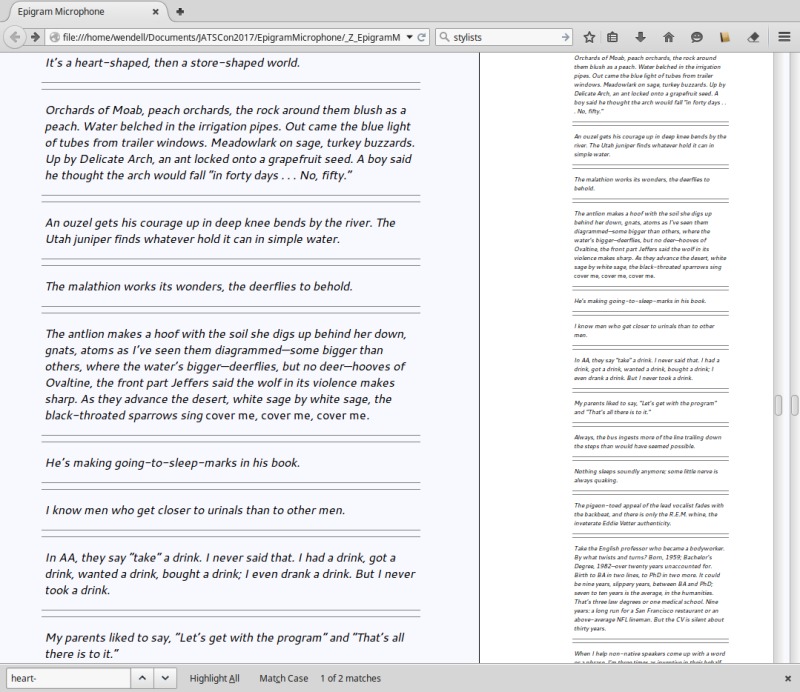
Fig. 3Finally BITS becomes us
Before the copy was finished, there was more editing. The screen shows XML+XSLT in the browser, as delivered in the demo package.
Early Conclusions
XSweet is designed to give tolerable and "good enough" results over arbitrary Word data, that is without any pre-formatting or configuration on the part of the Word user or data conversion specialist, for that matter. Of course this wasn't exactly the scenario being tested, since the consumer here (myself) intended precisely to use it as a front end. Nonetheless the question whether XSweet's results were good enough, must be answered affirmatively.
What is possibly more important is that XSweet's strategy of exposing and deferring some of the more complex problems of mapping, to a subsequent stage - by targeting an HTML vernacular representation of the phenomena of interest – was borne out. Epigram Microphone showed this working in several ways: a number of useful and important issues (for example relating to implicit sections, inset quotes and paragraph boundaries) were evident even in the HTML, making them available for repair – without going back to the Word document.
General issues aside, it is likely that XSweet will be more useful to other developers and service providers, rather than "end users" of JATS or even owner of JATS (who also have HTML) – since the step from HTML into JATS, is still considerable, irrespective of how that HTML is produced.
To serve as a useful component in a JATS or BITS-based workflow, XSweet would require some level of integration and customization – most likely commensurate with what would be required for other solutions. In that sense XSweet is not a panacaea nor even a threat to vendors (of tools or services) in the data conversion space. On the contrary they may be its biggest beneficiaries – since vendors and service providers may be just the people to do better with "good enough to improve".
This is because XSweet is fantastic for getting at the data, but no use for deciding what to do with it, or how to tackle that problem, either in general or "in the event" with one or another idiosyncratic (and demanding) source document. If the target is clear (a profile of BITS had the advantage of being fairly simple to define), appropriate to the data (Mark's essay sequence was almost a scholarly monograph and readily fit into BITS) – and a viable means available, to make from HTML mishmash into a better format (in my case, I had XProc/XSLT) – then XSweet makes that possible.
In the case of Epigram Microphone, all the work including conversion and JATS-based production (of HTML, EPUB and other outputs) surely compared favorably to what would have been possible using alternative technologies, especially given that we got BITS data out of it – thereby getting other benefits including stability, long-term legibility, and the further opportunities that may bring us.
References
- 1.
- Office Open XML Wikipedia page.
- 2.
- Adam Hyde, HTML Typescript - redistributing labor Posted Jan 2 2017.
Demo package
A zip package containing several intermediate versions of Epigram Microphone, as it was converted into BITS from Word, including HTML produced by XSweet as well as BITS produced by filtering that HTML further through XSLT making BITS. Both the "raw" (unedited) JATS/BITS is enclosed, and the final edited BITS XML.
In addition to these files, plain-text representations of the XML element structures of the (intermediate) HTML file, and the (final) BITS file, are included. They simply list elements from each document in a hierarchy so as to illustrate the differences once the full ("correct") structure has been interpolated and expressed.
A published version of Epigram Microphone is online at Pause Press.
What makes WordML difficult to convert
- Word documents are internally unstructured. What seems to be structure – chapters, sections, even lists – turns out to be façade appearing like structure from the outside, like a Hollywood set.It would be more accurate to say, it has a structure, but that structure has nothing to do with the "thing described" we are after when / as we ask questions about that thing we call "the document". Certainly there are no lines of text, no styling elements, but instead a set of sort of marionette-puppet theater instructions for how to "perform" the document (on screen in one or more modes, and as compiled by a printer driver or equivalent). WordML must be regarded first of all as a serialization of an object structure, native to Word's functional data model internals, as it has developed over time as a word processing application. Their correspondences to features of and in the "documents" we take them to represent, even when regular or systematic (which is not always the case) are also always nominal and provisional.
- Even at the level of running prose, Word internally provides nothing like "mixed content" in the XML sense. Instead, a Word document simply presents a sequence of "runs" of text (in XPath parlance they are all "siblings"), each of which is formatted.So where JATS or even HTML would represent bold nested inside italic, the Word shows bold-only followed by bold-italic followed by bold-only again.This kind of impedence mismatch also makes other challenges of data conversion (for example, mapping element types) more complex (since "conceptually it all has to happen at once").
- Most severely, Word documents typically exhibit no "descriptive semantics" or content type labeling of any consistent sort. There may occasionally be sporadic use of Word Styles, and information encoded by means of Styles may be important, but they are not consistent in any way that can be exploited by an automated processor. Even within a single document and always across multiple documents, inconsistencies (in labeling or style assignment) are more common than not.Instead, the information encoded in Word documents tends to be presentational, with rendering "instructions" (as it were) embedded directly. Instead of having a section header, what a World document will have, will be a line with an extra-large font, possibly in bold type. There being no way to determine definitively the possible significance of such a line of text, converting it into a descriptive format is never better than a reasonable guess.Note that successful conversion pathways from Word into JATS including proprietary solutions, may rely on the converse of this – namely, relying on expert users to provide Styles in Word data, instead of or in addition to "raw formatting". Their success and dependability comes from limting them to handle on Word documents that present this descriptive information – which is precisely missing in the general case and unavailable without such expert users. Accordingly, a limit of these tools is that a prior commitment must be made, even before exploring the data, to the target format, and expertise in using the tool, must be either found or made. Since neither this, nor the license for the tool, is free, XSweet might fit a small niche.
Of these three problems, only one is susceptible to a general solution, namely the second. The first problem depends on an issue of data modeling (that is, how appropriate structure is to be represented), while the third entails not only divining an appropriate data model, but also concerns itself with all kinds of "rich semantics", underspecified in the general case.
Yet if XSweet could help with the impedence-mismatch problem (including for example the difference between its "run"-oriented model, and the sorts of patterns of mixed content we expect to see in markup)- and thereby, simultaneously help with the severe problem of the opacity of WordML – perhaps the other problems have other solutions, in tools and workflows. If structure cannot be definitively established in data conversion, we can provide it later. Similarly, not being able to provide a consistent description or "good mapping" from any arbitrary Word document, into a structured format (such as JATS) – need not be an absolute impediment, if such a description can be provided to the data by some other means.
See some raw WordML data below.
Some raw Word data
Line breaks are introduced for legibility.:
<?xml version="1.0" encoding="UTF-8"?>
<w:p xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
w:rsidR="00000000" w:rsidDel="00000000" w:rsidP="00000000" w:rsidRDefault="00000000"
w:rsidRPr="00000000">
<w:pPr>
<w:keepNext w:val="0"/>
<w:keepLines w:val="0"/>
<w:widowControl w:val="0"/>
<w:spacing w:after="0" w:before="0" w:line="480" w:lineRule="auto"/>
<w:ind w:left="0" w:right="0" w:firstLine="0"/>
<w:contextualSpacing w:val="0"/>
<w:jc w:val="left"/>
</w:pPr>
<w:r w:rsidDel="00000000" w:rsidR="00000000" w:rsidRPr="00000000">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:cs="Times New Roman" w:eastAsia="Times New Roman"
w:hAnsi="Times New Roman"/>
<w:b w:val="0"/>
<w:i w:val="0"/>
<w:smallCaps w:val="0"/>
<w:strike w:val="0"/>
<w:color w:val="000000"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:u w:val="none"/>
<w:vertAlign w:val="baseline"/>
<w:rtl w:val="0"/>
</w:rPr>
<w:tab/>
<w:t xml:space="preserve">Of course, the zone can’t last; it isn’t the whole story.
Emerson knew the pressure and stress of the world, and asked himself repeatedly whether
literature in a democracy could be a vocation, a public service— and not an idleness,
an indolence, a slacking-off. But he couldn’t spend his time in questioning.
Writing always already is action. The idea can be found Aristotle, who defined
“action” as “a movement of the soul” in his </w:t>
</w:r>
<w:r w:rsidDel="00000000" w:rsidR="00000000" w:rsidRPr="00000000">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:cs="Times New Roman" w:eastAsia="Times New Roman"
w:hAnsi="Times New Roman"/>
<w:b w:val="0"/>
<w:i w:val="1"/>
<w:smallCaps w:val="0"/>
<w:strike w:val="0"/>
<w:color w:val="000000"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:u w:val="none"/>
<w:vertAlign w:val="baseline"/>
<w:rtl w:val="0"/>
</w:rPr>
<w:t xml:space="preserve">Poetics</w:t>
</w:r>
<w:r w:rsidDel="00000000" w:rsidR="00000000" w:rsidRPr="00000000">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:cs="Times New Roman" w:eastAsia="Times New Roman"
w:hAnsi="Times New Roman"/>
<w:b w:val="0"/>
<w:i w:val="0"/>
<w:smallCaps w:val="0"/>
<w:strike w:val="0"/>
<w:color w:val="000000"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:u w:val="none"/>
<w:vertAlign w:val="baseline"/>
<w:rtl w:val="0"/>
</w:rPr>
<w:t xml:space="preserve">. Soul is the coincidence of idea and action, the place where promise and performance become indistinguishable. “Utterance,” Emerson said, “is place enough.” His first publication, </w:t>
</w:r>
<w:r w:rsidDel="00000000" w:rsidR="00000000" w:rsidRPr="00000000">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:cs="Times New Roman" w:eastAsia="Times New Roman"
w:hAnsi="Times New Roman"/>
<w:b w:val="0"/>
<w:i w:val="1"/>
<w:smallCaps w:val="0"/>
<w:strike w:val="0"/>
<w:color w:val="000000"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:u w:val="none"/>
<w:vertAlign w:val="baseline"/>
<w:rtl w:val="0"/>
</w:rPr>
<w:t xml:space="preserve">Nature</w:t>
</w:r>
<w:r w:rsidDel="00000000" w:rsidR="00000000" w:rsidRPr="00000000">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:cs="Times New Roman" w:eastAsia="Times New Roman"
w:hAnsi="Times New Roman"/>
<w:b w:val="0"/>
<w:i w:val="0"/>
<w:smallCaps w:val="0"/>
<w:strike w:val="0"/>
<w:color w:val="000000"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:u w:val="none"/>
<w:vertAlign w:val="baseline"/>
<w:rtl w:val="0"/>
</w:rPr>
<w:t xml:space="preserve">... </w:t>
</w:r>
</w:p>
This converts into JATS as follows:
<p>Of course, the zone can’t last; it isn’t the whole story. Emerson knew the pressure and stress of the world, and asked himself repeatedly whether literature in a democracy could be a vocation, a public service— and not an idleness, an indolence, a slacking-off. But he couldn’t spend his time in questioning. Writing always already is action. The idea can be found Aristotle, who defined “action” as “a movement of the soul” in his <italic>Poetics</italic>. Soul is the coincidence of idea and action, the place where promise and performance become indistinguishable. “Utterance,” Emerson said, “is place enough.” His first publication, <italic>Nature</italic> ... </p>
Sorting out signal from noise is only a part of the challenge here. There are other difficulties as well:
- Mixed content in Word, isn't mixed. It's a sequence of formatted segments with no "nesting" even when that would be appropriate. Instead we get bold followed by bold-italic followed again by bold, etc.
- Markup in Word can be promiscuous as well as redundant. Very easily, we can get the equivalent of <i>Moby </i><i>Dick</i> Apparently Word doesn't clean up after itself after document edits.
- Formatting properties appear to be expressible in CSS - but only more or less. Some loss of fidelity is inevitable - while vital distinctions might still be preserved.
- There can be multiple ways to say the same thing in WordML, and things that appear the same may also be different (because they are marked for how they appear not what they are).
- At a superficial level Word offers help with textual apparatus such as footnotes and tables of contents, but these are quirky and unreliable.
Publication Details
Author Information and Affiliations
Authors
Wendell Piez.Copyright
The copyright holder grants the U.S. National Library of Medicine permission to archive and post a copy of this paper on the Journal Article Tag Suite Conference proceedings website.
Publisher
National Center for Biotechnology Information (US), Bethesda (MD)
NLM Citation
Piez W. HTML First?: Testing an alternative approach to producing JATS from arbitrary (unconstrained or "wild") .docx (WordML) format. In: Journal Article Tag Suite Conference (JATS-Con) Proceedings 2017 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2017.