

ALFA dbGaP Genotype Data Inclusion
Table of contents
Selection of Studies
Only studies that have genomic genotypes and that are marked unrestricted for the release of Genomic Summary Results (GSR) in concordance with the NIH GSR policy are selected for inclusion to frequency calculations. When the selected study has genotypes originating from multiple platforms (micro arrays or sequencing) the dataset resulting in the most genotypes is normally included. Preference for inclusion (BestSet) is also given based on the ease of processing as determined by dbGaP curation staff.
Sample Processing
Duplicate samples and closely related subjects are excluded from the calculations. Relatedness between each pair of subjects is derived from the pedigree file and determined using the GRAF software (Jin et all 2017) based on the genotypes. A pair of subjects is considered to be closely related, if either of the following is true: 1. The relationship of the two subjects is first degree or closer, i.e., identical twins, full sibling, or parent-offspring, as reported in the pedigree. 2. The two subjects have homozygous genotype mismatch rate (HGMR) 10% or lower, indicating they are first degree relatives or more closely related. If two subjects are closely related, the process randomly selects one of them for inclusion to the calculation. Within each study, subjects are selected so that no two subjects used are closely related. Across all studies, the software GRAF (Jin et al, 2017) is used to find all duplicate samples or identical twins to ensure that no two subjects used for PopFreq have identical or nearly identical genotypes.
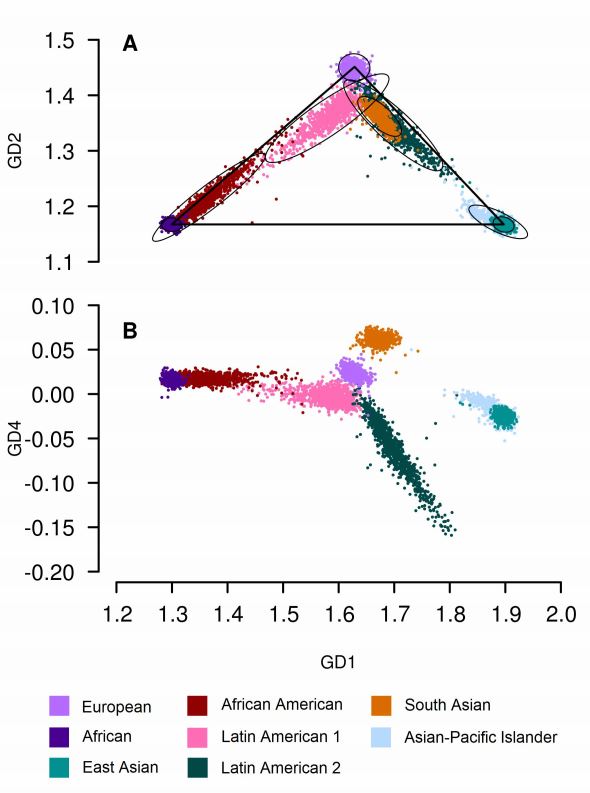
Populations are assigned to subjects based on both the study-reported populations and those inferred from genotypes using GRAF-pop software (Jin et al, 2019). All subjects are grouped into the following nine mutually exclusive populations based on the genotypes of 10,000 fingerprint SNPs.
Distributions of GRAF-pop scores of eight dbGaP study-reported populations: European, African (represented by study-reported populations Ghana and Yoruba), East Asian (represented by Chinese and Japanese), African American (including African), Latin American 1 (represented by Puerto Rican and Dominican), Latin American 2 (represented by Mexican and Mexican American), South Asian (represented by Asian Indian and Pakistani), and Asian-Pacific Islander (including East Asian but notSouth Asian) . For each population, 1,000 randomly selected subjects are plotted.
GRAF_pop Population reported on dbSNP RefSNP page.
| Name | Population Code | Description | BioSample ID |
|---|---|---|---|
| African Others | AFO | Individuals with African ancestry | SAMN10492696 |
| African American | AFA | African American | SAMN10492698 |
| African | AFR | All Africans, AFO and AFA Individuals | SAMN10492703 |
| European | EUR | European | SAMN10492695 |
| Latin American 1 | LAC | Latin American individiuals with Afro-Caribbean ancestry | SAMN10492699 |
| Latin American 2 | LEN | Latin American individiuals with mostly European and Native American Ancestry | SAMN10492700 |
| South Asian | SAS | South Asian | SAMN10492702 |
| East Asian | EAS | East Asian (95%) | SAMN10492697 |
| Asian | ASN | All Asian individuals (EAS and OAS) excluding South Asian (SAS) | SAMN10492704 |
| Other Asian | OAS | Asian individiuals excluding South or East Asian | SAMN10492701 |
| Other | OTR | The self-reported population is inconsistent with the GRAF-assigned population | SAMN11605645 |
| Total | TOT | Total (~global) across all populations | SAMN10492705 |
The population assignment employed in these calculations is conservative in comparison with the default in the GRAF-pop software. Populations are assigned using the following algorithm: 1. Assign a population to the subject using the default cutoff in GRAF-pop software (Jin et al, 2019). 2. Set the population to “Other” if this subject is not in the 95% confidence ellipse area of any population (1-8) as shown above. 3. If the subject has self-reported population, set population to “Other” if the self-reported population is inconsistent with the GRAF-assigned population.
References
Jin Y, Schäffer AA, Sherry ST, and Feolo M (2017). Quickly identifying identical and closely related subjects in large databases using genotype data. PLoS One. 12(6):e0179106
Jin Y, Schäffer AA, Feolo M, Holmes JB and Kattman BL (2019). GRAF-pop: A Fast Distance-based Method to Infer Subject Ancestry from Multiple Genotype Datasets without Principal Components Analysis. G3: GENES, GENOMES, GENETICS.