
 4.
4.Copyright Notice
Diabetes in America is in the public domain of the United States. You may use the work without restriction in the United States.
Bookshelf ID: NBK597726PMID: 38117926

An official website of the United States government

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Lawrence JM, Casagrande SS, Herman WH, et al., editors. Diabetes in America [Internet]. Bethesda (MD): National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK); 2023-.
Raymond J. Kreienkamp, MD, PhD, Benjamin F. Voight, PhD, Anna L. Gloyn, DPhil, and Miriam S. Udler, MD, PhD.
Author Information and AffiliationsInitial Posting: December 20, 2023.
Since early 2007, the establishment of international consortia and biobanks has catalyzed the performance of large-scale genomic studies. These efforts have driven an explosion in the discovery of genetic variation associated with type 2 diabetes. Most studies have involved genetic data captured using genotyping arrays populated by common single nucleotide polymorphisms (SNPs), although a rapid drop in the cost of next-generation sequencing has facilitated a growing number of exome and genome sequencing studies, which can capture increasingly rare variation. Hundreds of independent SNPs have been associated with type 2 diabetes and glycemic traits using genome-wide association studies (GWAS), and their numbers continue to increase. Findings have pointed to both known and novel molecular pathways and increased the understanding of fundamental disease biology.
On the other hand, causal variants have been identified for only a small fraction of the loci identified by GWAS, and a substantial proportion of disease heritability remains unexplained. While combining genetic variation into polygenic scores improves prediction of type 2 diabetes risk substantially beyond that of single variants, such scores are not yet used in clinical practice due to inadequate predictive ability and implementation challenges. Despite including millions of individuals, genetic studies remain limited by the diversity of populations represented, are underpowered to fully capture rare variation of modest effect sizes, and have incomplete ascertainment of alternate (non-SNP) forms of genetic variation.
As the community continues to expand genetic discovery and pursues systematic fine-mapping, platforms that focus on functional variation, systems biology approaches, and expansion to non-European populations, the coming years will witness exponential growth in our understanding of the genetic architecture of metabolic phenotypes related to type 2 diabetes. Whether these findings prove useful in disease prediction or therapeutic decision-making must be tested in rigorously designed clinical trials.
The explosive parallel growth in the prevalences of the related metabolic disorders of obesity and type 2 diabetes in much of the developed and developing world over the past few decades is almost certainly driven by environmental and behavioral factors, as genetic components do not change in an appreciable manner over such a short time. However, several lines of evidence suggest that variation in DNA sequence does contribute to type 2 diabetes risk. First, twin studies have shown that concordance for type 2 diabetes is greater for monozygotic twins (who share 100% of their DNA sequence) than for dizygotic twins (who, like siblings, share approximately 50% of their DNA sequence) (1,2,3,4,5). Second, the incidence of diabetes is much higher in certain racial/ethnic groups, despite environments that are relatively comparable to those of neighboring populations (6,7,8). Third, family history is an independent risk factor for the development of diabetes in population studies (9,10). And fourth, rare familial forms of diabetes, caused by mutations in single genes (hence, termed monogenic or Mendelian), prove that single base pair changes in the coding regions of key genes, which lead to alterations in protein sequence and function, are sufficient to cause hyperglycemia in the diabetic range (Figure 1) (11,12). Consistent with this notion, the estimated heritability of type 2 diabetes ranges from 25%–69% in a set of Scandinavian families (13) to 52% (95% confidence interval [CI] 26%–80%) in the Washington State Twin Registry (14) and as high as 72% in a large international meta-analysis of twin studies (15).
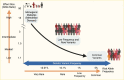
Taken together, these observations illustrate that rapid changes in the global epidemiology of type 2 diabetes are likely caused by environmental and behavioral factors overlaid on a background of genetic predisposition. This genetic predisposition may vary across populations, in some measure due to divergent genetic histories and unequal selection pressures in specific geographic regions; however, this is a topic of continued investigation (16).
Why is genetic exploration relevant? Regardless of whether genetic predictors become useful markers of disease onset or of subtypes in clinical practice, the identification of genetic variants associated with type 2 diabetes illustrates pathogenic mechanisms that may be targeted by future therapies. Because germline genetic variation always predates the onset of disease, the arrow of time establishes a causal relationship that is not evident with other biological associations. Thus, the genetic approach has a unique opportunity to shed light on the pathophysiology of diabetes in its various manifestations, helping to unravel its clinical heterogeneity and potentially refine therapeutic strategies. This article updates the information included in the Diabetes in America, 3rd edition chapter Genetics of Type 2 Diabetes (17).
Before a draft sequence of the human genome was available, genetic mapping depended on the generation and anchoring of anonymous genetic markers to specific locations in the genome. This task was first achieved by identifying variation in DNA fragments with known cleavage sites (restriction fragment length polymorphisms). Subsequently other markers, such as DNA segments with characteristic repeats (microsatellites) or unique stretches of DNA (sequence tag sites), enabled the introduction of more sophisticated methods (whole-genome linkage analysis and positional cloning) for determining the position of disease-causing genetic variation within the genome. Linkage analysis depends on the co-segregation of a causal mutation and nearby anonymous markers with affected, but not unaffected, members across successive generations in pedigrees. This approach has been successful for gene discovery in diseases that are highly penetrant: where disease-causing alleles are almost always found in individuals with disease and are almost always absent in individuals without disease. For diabetes, linkage analysis facilitated the discovery of the genes that underlie various types of monogenic diabetes, such as maturity-onset diabetes of the young (MODY) (12,18) or neonatal diabetes (19,20,21) (Figure 1); these associations are described in detail in Diabetes in America: Monogenic Forms of Diabetes (22).
However, diabetes is a complex disease, for which liability to disease is determined by hundreds to thousands of genetic variants that are only slightly penetrant and may carry interactions with the environment. Thus, the use of linkage analysis to characterize the genetic basis of common, complex forms of diabetes was far less successful. For type 2 diabetes, no single genetic locus of substantial effect analogous to type 1 diabetes loci exerts a very strong effect in the general population or even in individual family pedigrees. Thus, the effect of genetic variation is probabilistic rather than deterministic; a substantial proportion of people with some risk variants may be disease-free, whereas others who carry protective alleles may instead have type 2 diabetes due to a constellation of other factors.
To demonstrate the effect of genetic variation on human phenotypes, an alternative approach was needed. Association testing quantifies whether a specific allele is significantly overrepresented in diabetes cases compared to controls without diabetes. With large sample size, this method has greater statistical power to detect a common variant of weak effect. The major limitation of this approach was that—prior to 2005—only a handful of variants could be tested at a time, which required prior knowledge of the existence of genetic variants and prior biological knowledge of a role of a given candidate gene in diabetes pathophysiology. Although multiple genetic associations were described before 2005, only two of these have stood the test of time. Both variants change the amino acid sequence in genes that encode antihyperglycemic drug targets: the p.Pro12Ala polymorphism in the peroxisome proliferator-activated receptor gamma 2 (encoded by PPARG) (23) and the p.Glu23Lys polymorphism in the islet ATP-dependent potassium channel Kir6.2 (encoded by KCNJ11) (23,24). A third locus, a noncoding variant in the transcription factor 7-like 2 gene (TCF7L2), was discovered by large-scale association testing in areas of suggestive linkage (25). The TCF7L2 common intronic rs7903146 polymorphism had the strongest statistical association (though with a modest odds ratio ~1.4) seen consistently across multiple studies (Figure 2) (26,27).
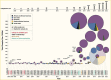
The panorama changed dramatically with the advent of genome-wide association studies (GWAS) (28). Several factors coalesced to enable GWAS: the discovery of millions of single nucleotide polymorphisms (SNPs) and their deposition in public databases; the manufacturing of genotyping arrays that could simultaneously query hundreds of thousands of SNPs with great precision and lower cost; the understanding of an underlying correlation structure between SNPs, driven by the finite number of recombination events in human history, which reduced the complexity of the variation to be interrogated; the recognition that the scientific imperative of reproducibility required the acceptance of strict statistical thresholds that accounted for the universe of possible hypotheses in the human genome; and the corollary of such awareness, that for these very small p-values to be achieved, very large sample sizes had to be assembled through international collaboration. Thus, for the first time, most common variants in the human genome (i.e., those with a minor allele frequency >5%) could be tested en masse (Figure 1).
Several independent GWAS (29,30,31,32,33) initially focused predominantly on European ancestry populations and, coupled with the growing scientific exchange that led to successive meta-analyses of ever-increasing size (34,35,36,37,38,39,40), produced a plethora of robust associations. This research changed the landscape of type 2 diabetes-associated variants, which grew from three prior to the GWAS era to several dozen leading up to 2018 and to more than 500 by 2022 (Figure 2). This list has been complemented by the implementation of similar approaches in the discovery of genetic determinants of quantitative glycemic traits (41,42,43,44,45,46,47,48,49,50,51) and other metabolic phenotypes, which share many signals with type 2 diabetes (Figure 3). Additionally, GWAS in non-European ancestry populations (52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73) and multi-ancestry meta-analyses of many of these studies (64,74,75,76,77,78,79) have identified hundreds of additional type 2 diabetes loci and demonstrated a large overlap in signals across populations. While a 2023 study suggested strong correlation in effect sizes among ancestries for type 2 diabetes (80), the largest GWAS for type 2 diabetes suggest some ancestry-correlated heterogeneity that may be explained by body mass index (BMI), which does vary across ancestries (81).
A particularly illustrative example of a combination of these approaches has been furnished by Moltke et al. (82). On studying the population isolate of Greenland, the study team selected a custom-made SNP array, the Metabochip (83), and focused on quantitative glycemic traits. The team followed up an original signal in TBC1D4 by sequencing the coding regions of this gene and identified a nonsense p.Arg684Ter variant of Inuit ancestry that is common in the Greenlandic population (frequency 17%) and associated with 2-hour glucose and insulin levels. Stop codon homozygotes harbor a tenfold increased risk of type 2 diabetes compared to wild-type allele carriers. Definitive identification of the implicated protein allowed for functional studies: the stop codon induces lower levels of the TBC1D4 protein in human skeletal muscle, causing reduced numbers of the glucose transporter GLUT4 and decreased insulin-stimulated glucose uptake, which lead, in turn, to postprandial hyperglycemia and impaired glucose tolerance.
The first generations of GWAS mainly tested genetic variation that is common across human populations (i.e., minor allele frequencies >5%). At first, only variants directly genotyped by the SNP arrays could be analyzed; subsequently, computational tools were developed to allow for statistical imputation that enabled accurate prediction of ungenotyped variants based on reference genome sequences (e.g., The 1000 Genomes Project Consortium (84)), which more readily allowed meta-analyses of variants tested in GWAS. As reference human genome sequence panels increased in sample size and diversity over time, three major developments occurred: first, high-accuracy imputation became possible for less common variants (i.e., allele frequencies <5%) (85,86); second, targeted genotyping arrays were designed that included less common but likely functional variation (e.g., coding variants) (87); and third, multi-ancestry GWAS analyses improved, with better capture of variants across ancestral groups (88). The combination of these techniques deployed from around 2017, coupled with the development of large population- and hospital-based biobanks, resulted in a dramatic increase in the number of discovered type 2 diabetes loci (Figure 2).
In addition to SNP arrays (which contain both protein-coding and noncoding variation), protein-coding arrays containing selected coding regions were developed with the hope of achieving a more direct link between associated signals and biological function. For example, using data from a genotyping array designed to focus on coding variation (i.e., the ExomeChip), Mahajan et al. identified 40 mostly common coding variant associations, including novel associations at POC5, PNPLA3, LPL, and ANKH (89). Interestingly, “fine-scale mapping” analyses (described further in the Determining the Function of Type 2 Diabetes Genes section) in this study indicated that often the associated coding variant was not the causal variant underlying the type 2 diabetes association signal. This finding suggested that a significant association between a protein-coding variant and disease was not enough to definitively implicate a gene in diabetes pathogenesis and may have identified the wrong gene altogether.
With the advent of new sequencing technologies, the cost of sequencing became dramatically reduced, enabling large-scale sequencing studies and discovery both within the protein-coding portion of the genome (the exome) (e.g., HNF1A p.Glu508Lys) (90,91,92,93), as well as from the full genome (94).
Gene burden analysis is an approach to implicate disease-causing genes by testing groups of variants within a gene together for their association with disease rather than testing single variants. This approach has become more feasible, including in type 2 diabetes, with the increase in the availability of sequencing data in large populations (Figure 4). Typically, the sets of variants within a gene aggregated for gene burden testing are those that are too rare to be tested individually (i.e., allele frequencies of ≤0.1%) and predicted to be functionally consequential (e.g., causing loss of gene function). For example, in a targeted gene burden analysis of SLC30A8, loss-of-function mutations were collectively associated with 65% reduction in risk of type 2 diabetes (95). Gene burden testing of all genes across the genome has also become increasingly possible with growing sequencing studies and development of high-throughput statistical tools. For example, Fuchsberger et al. performed a rare variant burden study in 12,940 individuals, although the study did not identify statistically compelling positive associations, which was likely due to a lack of statistical power (93). Subsequently, Flannick et al. performed gene burden testing using exome data from 20,791 type 2 diabetes cases and 24,440 controls and identified four genes (SLC30A8, MC4R, PAM, and UBE2NL) that were significantly associated with type 2 diabetes risk (91). More recently, large-scale exome sequencing in up to ~450,000 British subjects enrolled in the UK Biobank led to multiple additional gene-level associations with type 2 diabetes and glycemic traits, including some for genes known to cause monogenic diabetes (GCK, HNF1A, HNF4A, and PDX1), as well as novel diabetes genes (GIGYF1, MAP3K15, and FAM234A) (96,97,98,99).
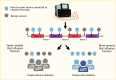
Despite rapidly growing study sizes, exome and genome sequencing studies remain limited by the power to detect single, low frequency variant and gene burden associations. An additional challenge is inference of rare-variant burden contributed by noncoding variants, which is especially difficult owing to the lack of meaningful and well-powered approaches to aggregation, which is a subject of active investigation (100,101). As sequencing becomes more routine across large biobanks, data from millions of subjects will likely help to identify a plethora of such associations for type 2 diabetes.
Once a region of the genome has been statistically associated with type 2 diabetes beyond reasonable doubt, new questions emerge, all of which are important to understanding genetic mechanisms and the viability of drug development. Such questions include: (i.) What causal variants underlie the signature of association? (ii.) What genes are causally implicated by these variants, and which tissues are etiologically relevant? (iii.) By what genetic and physiological mechanisms does variation in the region influence diabetes risk? (iv.) What direction of perturbation at this locus would be expected to produce a therapeutically beneficial effect on disease development and progression?
To identify where effort should be placed in the overwhelming space of functional experimentation, the research community has engaged in a variety of computational approaches to help prioritize candidate causal variants and genes for further work. For example, in focusing on the first question—identifying causal variants underlying an association signal identified by GWAS—the approach of statistical fine-mapping has been widely utilized (Figure 5) (102). This method can be conceptualized in two parts: first, locus fine-mapping, where the goal is to determine how many independent variants (or signals) contribute to the patterns of association observed in the region; second, signal fine-mapping, where the goal is to construct a “credible set” of variants statistically likely to harbor the true, causal variant for each identified signal. Fine-mapping methods can achieve these goals based on the statistical information alone; however, additional data can be used to further home in on the causal variant with that credible set. First, association data from multiple ancestries can narrow signals owing to different patterns of linkage disequilibrium (LD), meaning genomic variation that tracks together (77). In addition, annotations that label genomic sequences with a function due to their presence in either protein-coding sequence or noncoding sequence with presumed regulatory function (e.g., a promoter or enhancer) can be used to prioritize variants that are most likely to be driving the association signal (Figure 5) (38,77,103,104,105). These approaches are now routinely used in tandem. For example, in a 2022 multi-ancestry meta-analysis, the authors used both differences in LD across populations and functional annotation from diabetes-relevant tissues (e.g., DNA accessibility or chromatin state in islets, adipocytes, or hepatocytes) to determine the fewest number of variants that explained the genetic association at each signal (77).
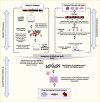
The second question—which genes are causally implicated by these variants—is challenging but must be addressed to enable appropriate mechanistic studies. It is worth remembering here that although a handful of signals identified for type 2 diabetes include coding variants in the credible set and thus provide a potential candidate gene, the majority of signals map exclusively noncoding variation without an obvious link to a candidate gene (89). As a result, different approaches have been utilized to link variants to genes to generate priorities for further study at the wet-lab bench. These approaches often combine empirical data derived from disease-relevant cell types (e.g., islets, adipocytes, hepatocytes, myocytes), including assessments of how the DNA is folded and which promoters interact with which enhancers (e.g., promoter capture Hi-C) or in silico methods that use known features, such as chromatin state, to predict which genes have altered expression due to a particular variant (Figure 5) (106,107,108). Combining such data in a probabilistic framework can provide estimates that a given gene is causal for type 2 diabetes (109,110). Initial functional studies focused on bulk tissue (i.e., human islets), but the advent of single-cell sequencing approaches allowed a shift to this higher-resolution approach (111,112). Most genes contain variants in their promoters that alter their expression, so it is very important to establish that signals for altered gene expression co-localize with those for diabetes risk (113,114). Advances in understanding the regulatory grammar of DNA have enabled machine learning approaches to predict variants that are most likely to alter gene expression in a given tissue (115,116). Understanding whether changes in gene expression result in a diabetes-relevant cellular phenotype is an important next step and is increasingly being assessed at scale through targeted and genome-wide cellular screening efforts (117,118).
Next, four examples of moving from “variant to function” are summarized, highlighting the challenges of this work, as well as the insights into disease biology that can be provided.
Coding variants provide a molecular “signpost” to the gene underlying the genetic association and have accelerated efforts to translate genetic discoveries into molecular mechanisms. The following examples showcase various approaches that can be taken to understand how genetic factors influence diabetes pathogenesis. For example, in 2007, a common coding variant (p.Arg375Trp) in SLC30A8 was identified in an early type 2 diabetes GWAS (29). SLC30A8 encodes a zinc transporter (ZnT8) that is located in pancreatic islet cells and is integral for zinc ion transport to stabilize insulin and trigger crystallization (119). Whether this diabetes-associated allele resulted in a loss or gain of function was not obvious. For years, there was uncertainty and debate as to how genetic variation in SLC30A8 influenced diabetes risk, since a common risk-associated allele from GWAS cannot inform on whether disease mechanism involves loss or gain of gene function, and mouse models did not have a consistent phenotype (120,121). Compelling evidence for the disease mechanism arrived in 2014 from a human gene burden analysis (Figure 4), described in the previous section, which showed that carriers of protein-truncating variants in SLC30A8 had a 65% reduced risk of type 2 diabetes compared to non-carriers, indicating that loss of function of the gene is protective for diabetes (95). In concordance, newer mouse models carrying the protective p.Trp138* allele had increased capacity to secrete insulin in high-glucose conditions, with secretion of 50% more insulin in response to hyperglycemia (122). Additional studies in humans supported these findings, demonstrating that particular loss-of-function missense mutations in SLC30A8 enhance proinsulin processing and insulin responsiveness to glucose, conferring protection against type 2 diabetes (123).
The SLC16A11 locus provides an illustrative second example both of discovery, this time in a non-European ancestry population, and of insight gained into disease biology from functional studies. A GWAS of populations in Mexico and East Asia first identified 17p13 as a type 2 diabetes genetic risk locus (67,69). The risk haplotype at this region is more common among individuals of Mexican or Latin American ancestry (minor allele frequencies ~30% compared to <2% in European populations) with each allele increasing diabetes risk by approximately 25% (67). Genetic fine-mapping at this locus revealed that some variants decreased SLC16A11 expression in liver, and other variants disrupted the interaction of the SLC16A11 protein (a monocarboxylate transporter) with basigin, a chaperone protein important for plasma membrane localization, leading to reduced cell-surface localization of the SLC16A11 protein (124). Homozygous carriers had up to 85% less SLC16A11 at the plasma membrane. SLC16 family members mediate transport of distinct substrates. Reduced SLC16A11 transport activity at the cell membrane results in alterations in fatty acid and lipid metabolism, driving cellular changes consistent with those seen with insulin resistance. As these findings implicated reduced SLC16A11 activity in risk for developing type 2 diabetes, increasing SLC16A11 function may offer a therapeutic target strategy.
The next example highlights the PAM locus, which was first identified in a glycemic trait exome-array study as harboring coding variants that alter beta cell function, as captured by the insulinogenic index (125). Initially, genetic data alone were insufficient to distinguish whether the association was due to the PAM missense allele or a second missense allele in near perfect LD in the neighboring PPIP5K2 gene. However, a second study in an Icelandic population identified a second missense variant in the PAM gene that was independently associated with altered type 2 diabetes risk, suggesting that PAM was more likely to be the effector gene at this locus (92). Subsequently, gene burden testing of missense variants predicted to be deleterious in PAM provided further support for the gene’s association with diabetes (91,98). Peptidylglycine alpha-amidating monooxygenase (PAM) is an enzyme in neuroendocrine cells that creates peptide amides, increasing peptide biological potency (126,127). PAM is widely expressed, including in both pancreatic beta and alpha cells, where it is involved in regulating insulin secretion (128). Type 2 diabetes-associated PAM alleles result in defective expression and reduced catalytic function, directly reducing pancreatic beta cell insulin content and impairing release in response to glucose (128).
A final example represents the more common signal that researchers need to dissect, as it is a regulatory variant. In an early study that combined fine-mapping with integration of genomic annotation from diabetes-relevant cell types, researchers established that the credible set of variants at the MTNR1B locus contained a signal variant. When they integrated the fine-mapping results with epigenomic data from diabetes-relevant cell types (e.g., pancreatic islets, hepatocytes), they showed that the variant was located in an enhancer and created a binding site for the transcription factor NEUROD1. Using in vitro cellular models, allelic-specific differences were found in NEUROD1 binding to the diabetes risk variant, and in human islets, the type 2 diabetes-associated allele was associated with increased MTNR1B expression (104). MTNR1B encodes the melatonin receptor, which is expressed in human beta cells and plays a role in inhibiting insulin secretion. The diabetes risk allele increases expression of the receptor and is predicted to reduce insulin secretion inappropriately.
As a polygenic condition, type 2 diabetes is well appreciated to be genetically determined by thousands of variants. Most genetic discovery, as noted, has involved common variants identified via GWAS, which exert only modest penetrance (i.e., odds ratios typically <1.2) (Figure 2). In isolation, such risk variants have little effect on disease risk; however, combining risk variants together into polygenic scores can improve risk prediction.
Polygenic scores estimating disease risk have been considered in two categories: (i.) “restricted-to-significant” polygenic scores (rsPS), which include only genetic variants significantly associated with disease, and (ii.) “global extended” polygenic scores (gePS), which typically include hundreds of thousands of variants, taking into account redundancy of signals related to correlation (i.e., LD) of variants (129). The ability of a polygenic score to predict future or prevalent disease risk has commonly been quantified using the area under the receiver operator characteristic curve (AUROC) or C statistic. The AUROC measures the predictive efficacy of a test, with a value of 0.5 indicating no greater predictive ability than chance and a value of 1.0 indicating a perfectly predictive test.
The first polygenic scores for type 2 diabetes were rsPS and included between three to a few dozen genetic variants identified in early genetic studies (including pre-GWAS candidate gene studies). While such scores had better predictive ability for future diabetes onset than any single variant, they offered AUROCs on the order of 0.60, which were insufficient for clinical use and inferior to prediction models involving clinical data alone (130,131,132,133). One of the largest rsPS for type 2 diabetes, including 62 SNPs, was tested in the Framingham Offspring Study (FOS) and produced an AUROC of 0.726 for incident diabetes prediction when combined with age and sex, which represented a significant (p<0.001), but minimal, improvement from the model with age and sex alone (AUROC 0.698) (133). Studies have demonstrated that polygenic risk for type 2 diabetes can be offset by environmental factors. For example, the Diabetes Prevention Program showed that an intensive lifestyle intervention, consisting of dietary and physical activity components, is effective even in the quartile of participants with highest type 2 diabetes rsPS (134).
More recently, methods to develop gePS have allowed capture of substantially more variants than in rsPS, including hundreds of thousands of variants with sub-genome-wide significant associations with disease (129). Multiple derivations of gePS for type 2 diabetes have demonstrated some improvement in risk prediction beyond rsPS. Still, even the most recently developed gePS have not generated prediction levels suitable for clinical use, with maximum AUROC estimates of approximately 0.73 in models that include age and sex (Figure 6) (38,135,136). Like the rsPS, the gePS have contributed only incremental improvement when added to models with clinical variables. For example, a model with age, sex, and BMI demonstrated an AUROC of 0.818 for prediction of prevalent diabetes status in the FinnGen Biobank compared to an AUROC of 0.835 when the model also included the gePS (77).

The predictive ability of polygenic scores is poised to improve with forthcoming methods that can incorporate rarer genetic variation. For example, a combined rare and common variant polygenic score was developed for glycated hemoglobin (A1c) (137). This combined polygenic score for A1c identified 4.9 million misdiagnosed type 2 diabetes cases in the United States due to inaccuracies in A1c representation of glycemia given erythrocyte variation—nearly 1.5-fold more people than a common variant polygenic score alone.
Another related application of polygenic scores is identification of individuals with particularly high disease risk. Different score thresholds can be chosen to pinpoint individuals at the greatest genetic risk of diabetes. For example, multiple studies have demonstrated that those in the top 10% of the type 2 diabetes gePS have approximately fivefold increased risk of type 2 diabetes compared to the bottom 10% and around 2.75-fold increased risk compared to the remaining 90% of the population (76,77). For individuals with such high polygenic type 2 diabetes risk, this genetic information could have clinical utility, and studies are ongoing to formally assess this possibility. At the same time, placing such risk estimates in the context of genetic testing for monogenic diabetes, which is performed as part of standard clinical practice, can be helpful. Rare genetic variants causing monogenic diabetes have been estimated in the UK Biobank to confer more than eightfold increased diabetes risk (138,139). Furthermore, in the UK Biobank, people with the highest 1% of the type 2 diabetes gePS were at significantly lower risk of diabetes, with ~20% disease prevalence compared to ~56% prevalence in monogenic diabetes carriers (Figure 6) (138). Further research is necessary to determine whether identifying individuals with high type 2 diabetes polygenic scores, who have essentially moderate disease risk, will be useful clinically. Additionally, even if deemed potentially useful in a particular context (e.g., as part of a clinical risk tool), implementation of polygenic score generation in clinical labs has many challenges, including determining the appropriate risk estimates for individuals of different genetic ancestries.
In addition to predicting future diabetes risk, a potential application of the type 2 diabetes polygenic score is clinical discrimination between type 1 and type 2 diabetes to improve accuracy of subtype designation. A 69-SNP type 2 diabetes rsPS was assessed for this purpose in the Wellcome Trust Case Control Consortium and was unable to provide strong discrimination between type 1 and type 2 diabetes cases (AUROC 0.64). This performance was inferior to a 30-variant type 1 diabetes rsPS, which had an AUROC 0.88 and was only minimally improved (AUROC 0.89) by the addition of the type 2 diabetes score to it (140). Thus, as of 2023, the type 2 diabetes polygenic score is unable to effectively aid diabetes subtyping; however, as described in the next section, additional strategies are being investigated to leverage type 2 diabetes genetic discovery for this purpose.
Type 2 diabetes is a heterogenous disease, with patients displaying varying degrees of pancreatic beta cell dysfunction and insulin resistance (141). In theory, genetics could identify underlying disease pathways leading to type 2 diabetes and allow stratification of patients based on their inherited risk for such pathways contributing to their disease process. The research field has a great interest in grouping type 2 diabetes genetic variants into shared mechanistic categories or pathways.
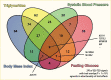
Prior to 2018, genetic clustering utilized approaches that restricted each locus to be a member of only one cluster, so-called “hard clustering” (36,89,142). These efforts identified some potential disease mechanisms, e.g., groups of loci broadly related to beta cell function and insulin resistance. However, loci with well-appreciated mechanisms were often not grouped in expected clusters, and some clusters were difficult to interpret. In 2018, two papers (89,143) suggested that applying “soft clustering,” where a locus could be involved with multiple pathways, could improve interpretability of genetic clusters. These two independent efforts also converged on a shared set of five clusters that could be readily linked to potential disease processes: two clusters related to distinct mechanisms of impaired beta cell function (termed beta cell and proinsulin by Udler et al. (143)) and three clusters related to different mechanisms of insulin response (termed lipodystrophy, obesity, and liver/lipid (143)) (Figure 7). A sixth, less well-defined cluster was identified by Mahajan et al. (89). Supporting a biological basis of the grouping of loci into clusters, the five clusters described in Udler et al. contained loci significantly enriched for active DNA regulatory elements that were specific to distinct tissues (e.g., the beta cell cluster loci were enriched in pancreatic islets).

A person’s aggregate genetic risk of loci in a given cluster is quantified by generating cluster-specific “partitioned” polygenic scores (pPS), which potentially capture risk for developing diabetes due to a particular disease process (143). In an analysis of ~17,000 individuals with type 2 diabetes, Udler et al. found that cluster pPS were significantly associated with distinct clinical features, suggesting that genetics could help disentangle the heterogeneity of type 2 diabetes. For example, an increased beta cell cluster pPS and proinsulin cluster pPS were each significantly associated with decreased C-peptide levels, supporting a shared disease mechanism of insulin deficiency. Additionally, the pPS could identify individuals with high risk specifically for a given genetic cluster. Thirty percent of individuals had a pPS uniquely in the top 10% of a single cluster, and these individuals also had distinct phenotypes compared to other individuals with type 2 diabetes. For example, those with extreme pPS for the lipodystrophy cluster had significantly decreased high-density lipoprotein (HDL), percent body fat, and BMI compared to all others with type 2 diabetes, mirroring the pattern of clinical phenotypes seen in patients with monogenic forms of lipodystrophy. Associations of the cluster pPS with distinct clinical phenotypes have been replicated in other datasets, and the pPS have differential associations with metabolic outcomes, including coronary artery disease, hypertension, and chronic kidney disease (144). For example, two clusters related to potential mechanisms of insulin resistance had opposite associations with coronary artery disease, with the lipodystrophy pPS increasing disease risk versus the liver/lipid cluster pPS decreasing risk. Subsequent expansion of the clustering work to include 323 type 2 diabetes variants and 64 trait associations identified 10 clusters, recapturing the original clusters along with additional clusters related to mechanisms of insulin deficiency and insulin resistance (145).
While genetic clusters have pointed to potential genetic mechanisms of type 2 diabetes, the currently derived pPS have small effect sizes and, as of 2023, are not useful for individual patient stratification in clinical practice. Nevertheless, analysis of cellular phenotypes in subcutaneous adipocytes derived from human biopsies has demonstrated differences in cellular features between individuals with high versus low lipodystrophy cluster pPS (146). Remarkably, cellular changes, such as the size of lipid droplets and intensity of mitochondrial staining, were visible on images, suggesting that while the effects conferred by the pPS on clinical biomarkers, such as serum lipid levels, may be small, there appear to be quite large effects on cellular features further upstream. As discussed in the Additional Insights Gained section, the specific cellular changes also point to convergence of polygenic and monogenic diabetes genetic pathways.
Genetic clustering has advanced simultaneously with clustering of individuals with diabetes based on clinical features (reviewed in Deutsch et al. (147)). Genetic analyses of some phenotypic diabetes clusters, including with use of pPS, have supported potential etiological differences in clusters (148,149). For example, Mansour Aly et al. demonstrated that in phenotypically derived clusters developed in Scandinavian populations (150), the two cluster pPS capturing forms of insulin deficiency (beta cell and proinsulin clusters) were both most strongly associated with their “Severe Insulin Deficient Diabetes” cluster (148).
The tremendous success of GWAS and their follow-up for type 2 diabetes and other human phenotypes has resulted in several insights into the genetic architecture of disease:
Pleiotropy is the idea that a single genetic variant or gene can have multiple, unrelated biological effects. Pervasive pleiotropy exists for loci associated with type 2 diabetes—with considerable complexity—which can be exploited. One notable observation following the success of association studies is the extent to which specific signals for type 2 diabetes often demonstrate association with a wider spectrum of additional traits, including cardiometabolic risk factors. Pleiotropy—a term used to describe this general phenomenon—turns out to be pervasive across the human genome (151). This phenomenon is nicely exemplified for type 2 diabetes by the glucokinase regulatory protein gene, GCKR. Genetic variation in this gene has been associated with numerous traits, including type 2 diabetes, serum triglyceride levels, and fasting glucose (152), as well as dozens of others. Genomic regions containing type 2 diabetes-associated loci display considerable shared associations with other cardiometabolic traits, including fasting glucose, systolic blood pressure, triglycerides, and BMI (Figure 3). Looking exclusively at the lead variant associated with type 2 diabetes at each of the 520 established signals reported to date, 71% carry nominal association (at a less rigorous p<1x10-3) with at least one of these traits; 10% carry association with three or four traits. Rather than focus on associations that are nearby, work in the 2020s has taken this analysis a step further, utilizing computational analyses to map the set of loci where these associations implicate a singular genetic change with multiple predisposing risk factors and increased risk to type 2 diabetes though formal statistical colocalization (153).
Beyond quantifying subtypes within the spectrum of diabetes patients, as discussed in the Genetic Stratification of Type 2 Diabetes section, multi-trait association data may be quite useful to indicate the expected physiological effect broadly if the target in the region were perturbed, i.e., “on target” effects beyond the central type 2 diabetes indication. For example, taking this approach and focusing on coding variation at the glucagon-like peptide-1 (GLP-1) receptor gene, Scott et al. contrasted the effects expected from genetic perturbation with GLP-1 receptor agonists, showing consistency with (lower) fasting glucose, but also evidence of lower risk for type 2 diabetes and coronary heart disease (154). Data and examples like this one can help prioritize targets with ideal physiological drug-targeting properties to maximize success in downstream safety trials, as well as to deprioritize targets that may be predicted to cause negative physiological responses through on-target perturbations.
Type 2 diabetes and monogenic diabetes overlap genetically. While large-scale genomic studies for type 2 diabetes have implicated many genes not previously connected to diabetes, variation near or within monogenic diabetes genes has been consistently associated with risk of type 2 diabetes (90,155,156). For example, in HNF1A, a gene causing a subtype of MODY, the p.Glu508Lys variant, which is present in 0.3% of people of Latino ancestry, was identified in exome sequencing of Mexican people and found to confer approximately fourfold increased risk of type 2 diabetes. In experimental models capturing its impact on gene expression, this variant demonstrated reduced transactivation activity of its target promoter at an intermediate level between the wild-type HNF1A protein and those with mutations causing MODY. Subsequent large-scale sequencing studies, as noted, have demonstrated that individuals with type 2 diabetes carry more rare variants in monogenic diabetes genes than would be expected by chance (91,96,157). Additionally, type 2 diabetes risk variants generating the lipodystrophy cluster pPS (143), as described in the Genetic Stratification of Type 2 Diabetes section, define a cellular phenotype in human subcutaneous adipocytes (involving increased mitochondrial activity and decreased lipid accumulation) that mirrors cellular changes seen in monogenic lipodystrophy (146). Together, these findings suggest that patients with monogenic diabetes and type 2 diabetes exist along a continuum rather than in discrete binary categories. Further supporting the idea of a continuum, population-based studies of people with pathogenic genetic variants expected to cause monogenic diabetes have demonstrated less severe clinical phenotypes than classically described (138,139).
Genetic studies augment prior epidemiological observations. Several of the strongest genetic associations for BMI (e.g., the FTO-IRX3-IRX5 and MC4R loci) are also strongly associated with susceptibility to type 2 diabetes. Furthermore, the alleles that increase BMI also increase susceptibility to type 2 diabetes, which is broadly consistent with prior epidemiological studies. This result is fully expected because BMI is a causal risk factor for type 2 diabetes. One would expect that genetic variants that modify any type 2 diabetes causal risk factor should also modify type 2 diabetes susceptibility. This idea can, thereby, be used to generate novel discovery: that is, the observation that genetic variants associated with an exposure in aggregate also modify type 2 diabetes susceptibility is evidence that this exposure is causal.
Under specific assumptions, potential causal exposure/outcome hypotheses can be statistically evaluated by using genetic variants for the exposures in an instrumental variable analysis framework (158). This framework, dubbed Mendelian randomization, has seen dramatic expansion and utilization in the last decade, given the substantial growth of genetic association data, to search broadly for causal risk factors for disease. In the context of type 2 diabetes, this approach has led to some interesting (perhaps provocative) statistical observations (159). For example, genetically elevated testosterone levels increase susceptibility to type 2 diabetes in women, but decrease type 2 diabetes risk in men (160). In contrast to the well-established protective effects of lower low-density lipoprotein (LDL) on heart disease, reduced LDL cholesterol levels may increase susceptibility to type 2 diabetes (161,162). For example, there is a higher risk of type 2 diabetes in individuals who take statins, which lower cholesterol levels (163), and a lower prevalence of type 2 diabetes is observed in patients with familial hypercholesterolemia (164). Distinguishing between correlation and causality for these observations is certainly a key objective for future work.
Despite the overwhelming success of large-scale human genetic studies in advancing knowledge of the genetic determinants of type 2 diabetes, a number of limitations must be recognized. These limitations have been identified by the research community and are being addressed to complement gaps in our understanding.
Persistent overrepresentation of individuals of European ancestry in GWAS. The past 15 years have seen a welcome and much-needed increase in the diversity of population groups where GWAS for type 2 diabetes have been performed. These groups include East Asian (56,57,58,59,60,61,62,63,69,71,165), South Asian (53,65,66,78), African American (54,70,76), Latin American and Hispanic (52,55,67,76), and Native American (68,75) populations (Figure 2). As consortia assembling these data perform large-scale, multi-ancestry meta-analyses (75,76,77,165), more novel findings are expected to come to light. Still, even if all existing data were combined, the proportion of samples for the genetics of type 2 diabetes would not reflect the national distribution of these groups across the United States, much less the distribution of these populations across the world. To maximize the power for discovery and the translational benefits of these discoveries for everyone, continued inclusion efforts at scale in GWAS and generally in multi-omics resources are essential. DNA Biobanks—like those of the Million Veteran Program (MVP) or the All of Us cohort, to name a couple—are poised to close some of the gaps, although additional efforts to expand collections and integrate with existing data are a clear direction of growth in years to come.
Polygenic scores derived from European populations do not translate well across other ancestral groups. As polygenic scores have been developed primarily in European populations, prediction has been most accurate in populations of matched ancestry, with poorer performance in other groups. For example, the performance of the 23andMe gePS score published in 2019 declined from an AUROC of 0.652 in a people of European ancestry to 0.588 in those of African American ancestry (136). Trans-ancestry polygenic scores are being developed using modeling to derive variant weights without the need for a priori population assignment (e.g., Ge et al. (166)). However, such scores still suffer from relatively low AUROC values, reflecting the need for further refinement before clinical applications are possible.
Most analyses have not considered interactions with the environment and sex. Type 2 diabetes results from complex interactions among multiple genetic and environmental factors, and the rapid rise of its prevalence cannot be attributed to genetics. Because most GWAS are designed to detect loci that have primary effects on type 2 diabetes risk, regardless of the environmental context, many variants whose impact varies according to an environmental parameter might be missed. This effect is due in part to the imprecision inherent to environmental measures and the noise introduced by a single cross-sectional environmental exposure. In contrast, genotyping methods are extremely accurate, and the genetic exposure is uniform across an individual’s lifetime. Nevertheless, analytical methods are being developed that allow for the joint inquiry of main gene effects and gene × environment interactions (167). These methods have already been deployed to identify loci for insulin sensitivity (43) and the regulation of BMI (168). In the future, genetic biobanks that are richly phenotyped, where environmental factors on diet, geography, or other factors are included, may offer the potential to further advance studies of gene × environment interactions. For example, a 2022 study reported numerous loci associated with a collection of physical activity traits (169), and identifying specific physical activity × type 2 diabetes interactions is a clear direction for future research. Finally, new statistical methods are available that can also identify effects of gene × environment even when the exact risk factor is not known (170). These methods are limited only by statistical power, and thus, the samples sizes provided by biobanks are uniquely powered for this type of discovery effort.
A second variable routinely included in genetic association studies of type 2 diabetes is biological sex. However, sex-stratified analyses have been performed for type 2 diabetes (39,165) and fasting glucose/insulin (49) to identify associations that may differ between sexes. While a scant handful of loci appear to have differences between sexes, this heterogeneity can be of epidemiological interest. For example, in a large-scale study in individuals of East Asian ancestry, Spracklen et al. identified a compelling type 2 diabetes association in males but not in females at the ALDH2 locus (165). ALDH2 is a well-known locus related to alcohol metabolism, suggesting that difference in type 2 diabetes susceptibility attributed at this locus may be explained in part by behavioral differences in alcohol consumption between sexes and the downstream effects on metabolic traits this may impart (165,171).
Progress on understanding the genetics of complications of diabetes. While large-scale genetic studies for type 2 diabetes have been performed, progress on understanding the basis of risk for diabetic complications has met with variable success depending on the trait. Certainly, environmental factors, particularly glycemic control, have a large effect on the risk of developing complications. Yet, these factors do not completely explain the risk for complications, which is further influenced by genetic background. Knowledge of genetic contributions to relatively common traits for which people with diabetes are at elevated risk has advanced significantly, including for coronary artery disease (172), peripheral artery disease (173), stroke (174), and chronic kidney disease (175). However, genetic loci that specifically elevate risk of these complications in type 2 diabetes patients have not been obviously detected despite relatively large sample sizes, for example in coronary artery disease (176). Thus, the excess risk for these conditions that is conferred by type 2 diabetes has not been explained. With complications specific to diabetes—diabetic retinopathy, diabetic kidney disease, or diabetic neuropathy—advances have been limited by the lack of sufficient well-phenotyped samples. Potentially, biobanks that are richly phenotyped may offer a pathway to address this challenge, e.g., predicting diabetic retinopathy using a type 2 diabetes polygenic risk score (76). However, electronic health record data, from which a diabetes complication phenotype could be defined, are quite noisy and require substantial effort to construct high-quality, accurate phenotypes where the proper order of disease progression to complication can be determined. Pooling efforts across multiple biobanks to make progress on understanding excess risk for complications, as well as predicting which type 2 diabetes patients are most liable to develop various comorbidities, offers a very promising direction for future work.
Most analyses are simple additive tests for association and do not explore more complex modes of inheritance. There are good statistical reasons for this approach, a model in which the presence of two copies of the risk allele in an individual essentially doubles the risk associated with a single allele. This assumption may not always be the case: in the two extreme examples, under a dominant model, two copies of the risk allele will not add any further risk to that conferred by a single copy, and under a recessive model, the risk will not be made manifest unless both copies are present. O’Connor et al. conducted a GWAS using a recessive model for type 2 diabetes and identified 51 loci associated with type 2 diabetes, including five variants undetected by prior additive analysis (177). One low-frequency variant, rs115018790, which colocalization analysis linked to reduced expression of PELO, had an odds ratio of 2.56 for type 2 diabetes in homozygous carriers. While most type 2 diabetes-associated SNPs exert their action via an additive model, this is expected as their discovery took place precisely under such a model. A comprehensive examination of alternative modes of inheritance is needed in existing GWAS datasets, which now are reaching adequate sizes to compensate for the smaller number of homozygous minor allele carriers and for the penalty incurred by additional statistical testing. Similarly, tests of gene × gene interactions (epistasis) and accounting for divergent effects depending on parental line of inheritance, where that information is available (178), are likely to yield additional loci.
Given the rapid progress achieved in genetic discovery in type 2 diabetes and the multipronged approach deployed to overcome experimental limitations, the research community holds great hope that the pace will be maintained and a substantial part of the genetic architecture of type 2 diabetes will be elucidated in the coming years. If this vision is realized, several conceptual advances can be expected:
The nosology of disease will be refined. Type 2 diabetes, diagnosed solely on the basis of the final common pathway of hyperglycemia, is likely a heterogeneous syndrome that can be caused by a variety of processes (179). Genetic etiologies have already helped classify the various forms of monogenic diabetes, and an analogous genetic subclassification of type 2 diabetes informed by physiology is beginning to emerge (e.g., Udler et al. (143)).
Additional disease pathways will be identified. Unsuspected biology has already been uncovered via genetic discovery. For example, human genomic studies followed by elegant functional studies of TM6SF2 and PNPLA3 have implicated liver lipid metabolism in the pathogenesis of both type 2 diabetes and fatty liver disease (180). The increasing number of genetic loci at hand and availability of -omics tools (e.g., transcriptomics, epigenomics, metabolomics) will facilitate discovery and refined understanding of disease pathways, some of which may be amenable to the development of new therapeutics.
Genetic discovery may identify drug targets. Among the initial type 2 diabetes genetic associations were coding variants in PPARG, the gene that encodes the target of thiazolidinediones (23), and KCNJ11/ABCC8, the genes that encode the targets for sulfonylureas (24,181). More recent studies have identified the target for GLP-1 receptor agonists as another type 2 diabetes-associated gene (182,183). Additionally, multiple companies have developed glucokinase activators, which piggyback on years of research of GCK’s role in regulating glucose homeostasis and causing MODY (41,184,185). While debate continues around whether glucokinase activators are a safe and effective treatment for diabetes (186,187,188,189), all of these examples represent proof of principle for the potential for genetic discovery to aid drug development. Aggregating -omics data in humans and model systems, as well as ancillary associations that might point to off-target effects, will be essential for the genomic revolution to catalyze new drug discovery.
Treatment paradigms will be modified. Pharmacotherapy in type 2 diabetes is often selected based on patient comorbidities, medication side effects, cost, and availability, without consideration of the underlying pathophysiology driving disease phenotype (190). Pharmacogenetics is a promising precision medicine approach to tailor treatment choices by a patient’s underlying genetic background (191,192). Specific loci have been implicated in the response to metformin (193,194,195), sulfonylureas (196), and GLP-1 receptor agonists (197,198,199,200). Using genetics to guide medication selection might orchestrate a greater improvement in A1c, decrease risk for comorbidities, or suggest lower medication doses, reducing side effects.
Stratification of patients may allow for better targeting of public health or clinical trial interventions. Some preventive or therapeutic measures may be too expensive to deploy in the population at large, or they may be futile in specific subgroups. Genetic characterization may help identify the groups of people more likely to benefit from particular public health strategies, for example, those at highest genetic, as well as socioeconomic, risk (201). Similarly, the efficiency of clinical trials may be enhanced by enrolling participants who are more likely to reach the desired endpoints or benefit from the agents being tested, as has been demonstrated already for an atherosclerotic disease gePS in a trial for evolocumab (202).
Genetics may facilitate the implementation of precision or personalized medicine. Though it is not yet clear that genetic information will be powerful enough to apply therapeutic decisions at the individual level, it may help do so for specific subgroups. For example, genetic approaches may identify groups of individuals who are more likely to develop a particular diabetes complication. For such an approach to be feasible, researchers envision that in the not-too-distant future any individual who joins a public or private health care system would be genotyped or sequenced for the full list of actionable genetic variants (e.g., those that modify risk of common diseases or response to available medications), such that his/her information is available in the electronic medical record. When the time comes to make specific screening or therapeutic decisions, genetic information filtered through appropriate decision support tools would automatically guide the practitioner into the course of action most appropriate to the person and situation at hand.
Large-scale consortia efforts are critical for advancement of precision medicine. The genetics community has demonstrated the value of large-scale collaborative science for the development and deployment of novel methods and the discovery of robust disease associations. As the field accelerates efforts to move from genetic discovery to molecular mechanism, this ethos needs to be extended to capture new communities and data types. The International Common Disease Alliance (ICDA) seeks to catalyze these efforts by bringing expertise together, thus reducing redundancy and increasing efficiency. For type 2 diabetes, the Accelerated Medicines Partnership for Common Metabolic Disorders (AMP-CMD) provides a focus for the diabetes community, initially bringing genetic and genomic data together, but increasingly extending this to epigenomic and cellular data. The American Diabetes Association (ADA) and the European Association for the Study of Diabetes (EASD) support efforts to provide consensus guidelines on how genetics can be incorporated into precision medicine efforts for diabetes diagnosis, prognosis, and treatment. Moving forward, all efforts must be inclusive and aim to reduce health disparities.
In summary, the field of type 2 diabetes genetics has experienced a steep discovery curve, and efforts now focus on translation of findings to improve understanding of pathophysiology and augment disease risk prediction. Progress has been uneven, with most efforts focused on common variants and populations of European ancestry. However, concerted efforts are being made to improve the diversity of genetic studies, in part facilitated by the emergence and growth of biobanks. Larger and more diverse study populations with both clinical and genetic phenotyping, along with the improving affordability of sequencing technologies and the continued development of analytical tools, contribute to an optimistic outlook for the future. Whether this newfound knowledge will translate into improved patient care depends on the success of basic science to identify causal risk genes and their mechanisms, the development of polygenic scores with enhanced predictive ability, and the opportunity to design and execute genetically based and outcomes-driven clinical trials.
glycated/glycosylated hemoglobin
area under the receiver operator characteristic curve
body mass index
global extended polygenic score
glucagon-like peptide-1
genome-wide association study
linkage disequilibrium
maturity-onset diabetes of the young
peptidylglycine alpha-amidating monooxygenase
partitioned polygenic score
restricted-to-significant polygenic score
single nucleotide polymorphism
Dr. Kreienkamp is supported by a training grant from the National Institute of General Medical Sciences (T32GM774844). Dr. Voight is supported by a grant from the National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK; UM1DK126194). Dr. Gloyn is a Wellcome Senior Fellow in Basic Biomedical Science and is funded by Wellcome (200837), the NIDDK (UM1DK126185), and the Stanford Diabetes Research Center (P30DK116074). Dr. Udler is supported by the NIDDK (K23DK114551, R03DK131249), the Clinical Scientist Development Award from the Doris Duke Charitable Foundation, and the Massachusetts General Hospital Transformative Scholars Award.
The authors thank Jason Flannick for code and time provided to help generate Figure 2 and Kirk Smith for his assistance in developing Figure 7.
This is an update of: Florez JC, Udler MS, Hanson RL: Genetics of Type 2 Diabetes. Chapter 14 in Diabetes in America, 3rd ed. Cowie CC, Casagrande SS, Menke A, Cissell MA, Eberhardt MS, Meigs JB, Gregg EW, Knowler WC, Barrett-Connor E, Becker DJ, Brancati FL, Boyko EJ, Herman WH, Howard BV, Narayan KMV, Rewers M, Fradkin JE, Eds. Bethesda, MD, National Institutes of Health, NIH Pub No. 17-1468, 2018, p. 14.1–14.25
Received in final form on August 23, 2023.
Drs. Kreienkamp, Voight, and Udler had no financial disclosures to report. Dr. Gloyn’s spouse holds stock options in Roche.
Diabetes in America is in the public domain of the United States. You may use the work without restriction in the United States.
Your browsing activity is empty.
Activity recording is turned off.
See more...